高阶 | 使用神经网络对网络资源自动分类——以校花贴吧图片为例

本来这一篇应该在两个月之前就写完的,但是众所周知在家=生产力0这样一条定律限制了老潘。所以在大量粉丝取关之际,赶紧把这篇推送搞上来,诚挚为已经取关的同学没法看完本系列作而深感遗憾。
本篇继承“高效获取互联网资源”这一主题,并引进目前非常时髦的神经网络技术,实现前文进阶 | 利用Python开挂式获取网络资源——以搜集贴吧图片为例的后续功能开发,为广大挂逼网友创造自动分类校花与水图表情包的自动分拣机。
摘要
本项目以百度贴吧众多图片作为待分类数据,通过最少的操作步骤,实现了在Keras环境下使用以ImageNet为预训练权重的ResNet50网络进行图片分类。分类效果比较好甚至不需要对模型进行什么改动,最终实现了从杂乱图片中筛选包含目标主体的图片。针对包含人体人像这类图片,调用了Face++进行识别,做到了识别图片中是否包含人像和人像的性别颜值打分(并没有)评判。项目整体准确度一般,只能作为娱乐项目玩一玩。
绪论
当某同学阅读完本系列前一作,兴致勃勃的把程序复制-粘贴下来之后,准备上贴吧去抓取校花,却不料被现实绊倒,迷茫在表情包的海洋中。
虽然可以像一个痴汉去手动地一个一个检查哪个图片是美女哪个图片是表情包,但是一来会让同学们身体被掏空,二来也丧失了高效获取信息的初心。所以为了使各位同学身体健康心情愉悦,一个自动分拣照片的设备是非常必要的。
众所周知,近年关于图像分类的技术已经非常成熟,我们可以易如反掌的做一个自动分类机出来,但是里面涉及若干技术细节,了解这些细节既有助于各位同学保持健康了解一些神经网络的科普知识,又有助于大家学习一些Python的奇技淫巧。
一、神经网络是啥
之前老潘和一个同学针对神经网络进行过一些探讨,趁着这个时候回忆了一下当时我们探讨得出的一些看法。
众所周知,平时使用计算器的时候,需要在键盘上输入待计算的数字和算符,之后显示器会显示计算结果。
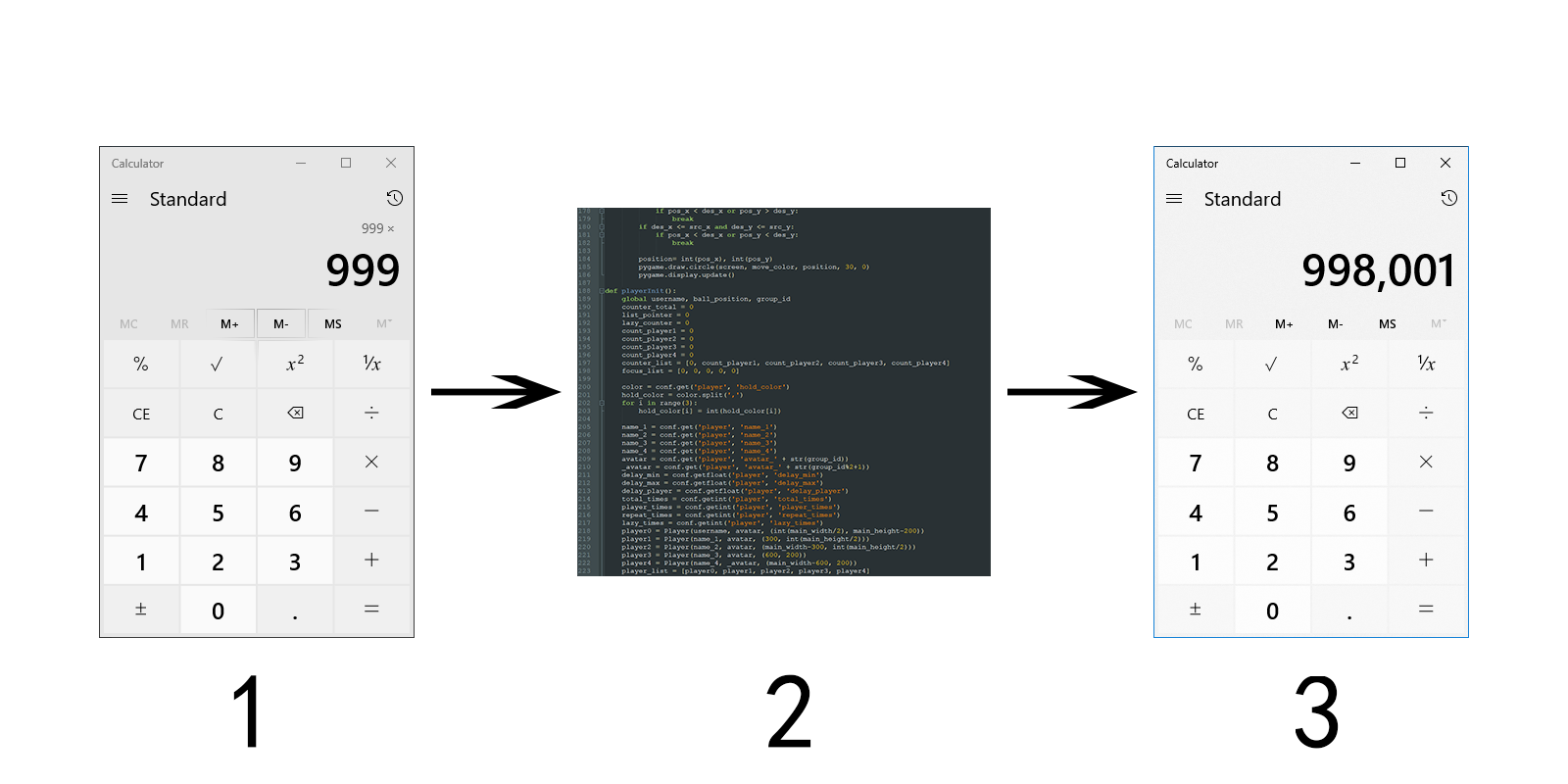
计算器算数的过程无非就是(1):拿来要算的东西(2):放进某种程序或者电路中(3):把算完的结果再拿给你。这其中我们只能看到算前的式子和算后的结果。
那么神经网络运作类似,(1):拿来要算的东西(2):放进某种神经网络中(3):把算完的结果再拿给你。这其中我们只能看到算前的东西和算后的结果。
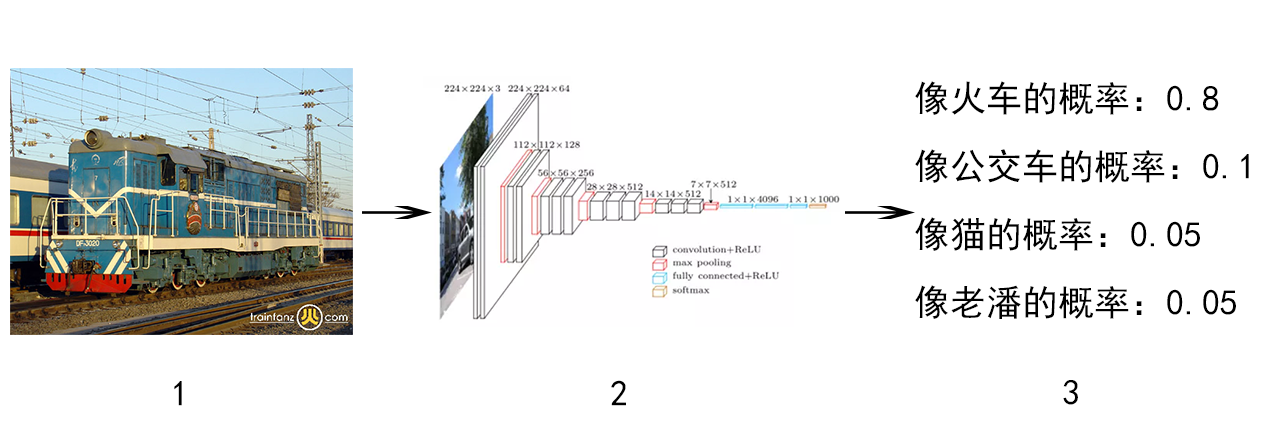
但是神经网络和普通计算器的区别在于,计算器输入只限数字和计算符号,输出一般就是一个数字或者其他化简后的算式。神经网络输入的东西形式多种多样,图片/声音/人脸/你的购买记录……输出的结果多种多样,例如算一下你的脸像猫的概率,算一下把你的声音变成老潘的声音是什么样的,算一下你双十一最可能买的东西……
计算器可以设计各种按钮接受一二三四五加减乘除号,神经网络也可以设计各种“类似按钮”接受图片声音购买记录。计算器用屏幕或者数码管显示计算完的结果,神经网络用列表显示这个输入的结果算完之后更像哪一个类别。那么具体这个网络怎么计算,怎么分类,分几类,就是各位调参工程师的工作了。
所以当时讨论的结果是,神经网络实质上是一个超大型的计算器。
有一个图片来描述人工智能,机器学习,深度学习,神经网络这些名词之间的关系:
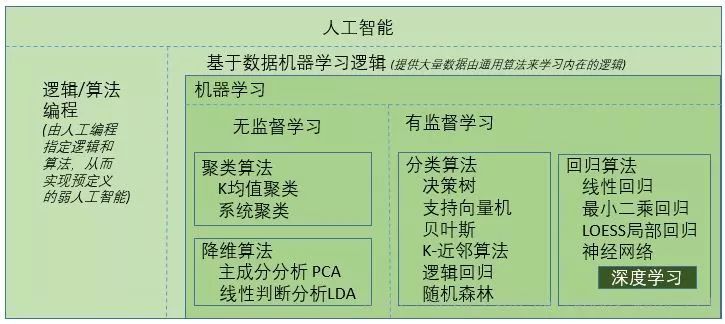
人工智能,机器学习,神经网络,深度学习的关系:https://blog.csdn.net/lemonade_117/article/details/82668084
二、怎么用神经网络“计算”
如果自己从头仿照主流的神经网络搭建并且用数据集训练,耗时巨大而且需要超强劲的设备。即使自己勉强训练出来,得到的结果一般也比不上Google等一票大团队使用超大数据集超强劲显卡超贵的电费训练好给大家用的预训练模型。直接拿这些模型来简单用一用已经足够,如果有特殊需求或者特殊的数据,还可以使用微调来做迁移学习。(名词:训练,科普解释为:通过设定好的一种算法,给一批题目和答案,让神经网络自己配置内部权重)
2.1 ResNet
这里使用ResNet50,加载ImageNet的预训练权重来试一下图片分类。(名词:权重,科普解释为:类比于计算器内部的接线和电路)
首先导入需要的库:
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
加载模型,参数weights是加载预训练权重,否则使用随机化权重,include_top是指定是否包含顶部全连接层,全连接层最终输出这个图片属于每个类别下的概率,这个参数可能用于迁移学习。
model = ResNet50(weights='imagenet', include_top=True);
接下来把结果预处理一下,输进去,获取到结果:
img_path = 'test/4.jpg'; #加载图片
img = image.load_img(img_path, target_size=(224, 224)); #由于包含全连接层所以需要固定图片尺寸
x = image.img_to_array(img); #图片转成数组
x = np.expand_dims(x,axis=0); #增加一维
x = preprocess_input(x);
preds = model.predict(x);
通过matplotlib把结果统计并显示出来:
import matplotlib.pyplot as plt #加载绘图库
print('Path:',img_path, '\nPredicted:', decode_predictions(preds, top=8)[0]); #decode_predictions如果不指定top参数默认显示概率最高的前5个,指定几个显示几个
plt.figure(figsize=(8,8)); #默认plot图太小了
plt.subplot(2,1,1); #类似MATLAB画子图
plt.axis('off'); #关掉这里的坐标轴
plt.imshow(plt.imread(img_path)); #显示原图像
name_list = [decode_predictions(preds)[0][i][1] for i in range (0, 5)]; #关于列表推导式的使用见参考文献
num_list = [decode_predictions(preds)[0][i][2] for i in range (0, 5)]; #decode_predictions(preds)出的是一个嵌套结构的list
plt.subplot(2,1,2);
plt.barh(range(len(num_list)),num_list, tick_label = name_list); #把各类概率画个条状图
plt.show();
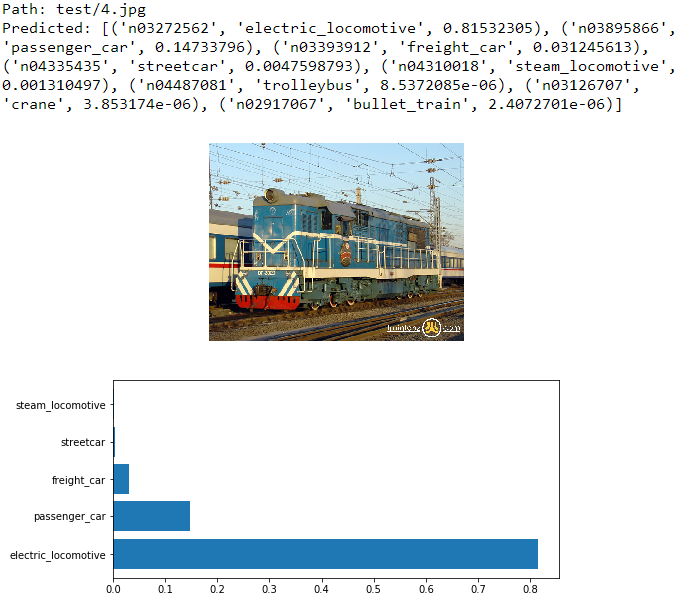
实际测试一下看看效果
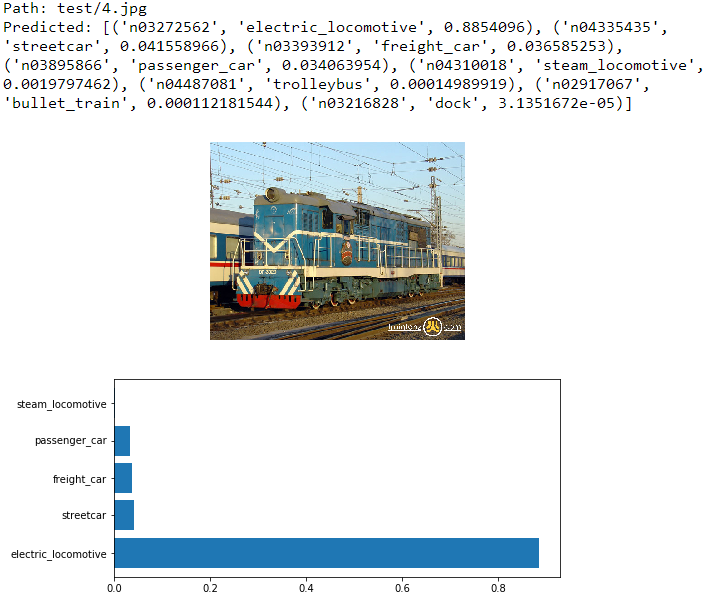
2.2 VGG
使用VGG16,基本步骤和上一节几乎一模一样,只是需要修改一下调用的库和加载的模型即可:
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input, decode_predictions
model = VGG16(weights='imagenet', include_top=True)
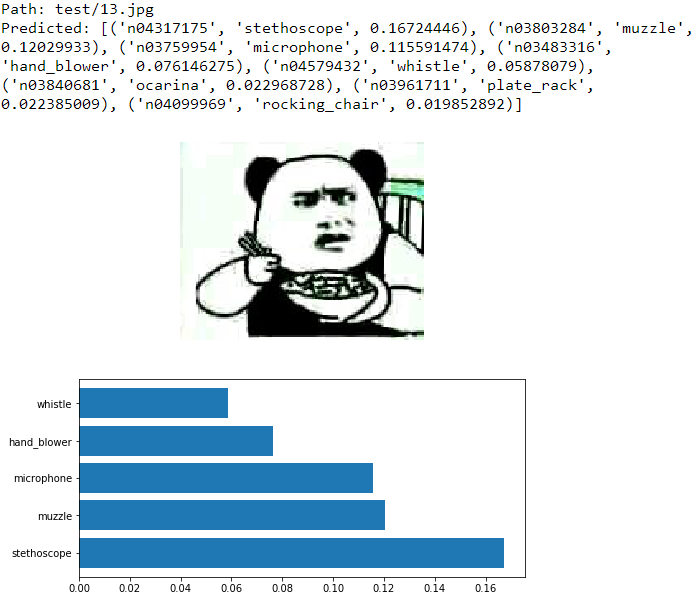
实际测试效果与ResNet差别在于最高概率之外的识别结果稍有不同,但是对主体都能比较清晰的分出来。至于表情包水图,结果更杂乱了。有一个想法是,可以用两个网络对结果分两次类,即使真的有水图被误分进目标类别,也能够再被检出来?这个留作课堂作业,下课交给各班学委。
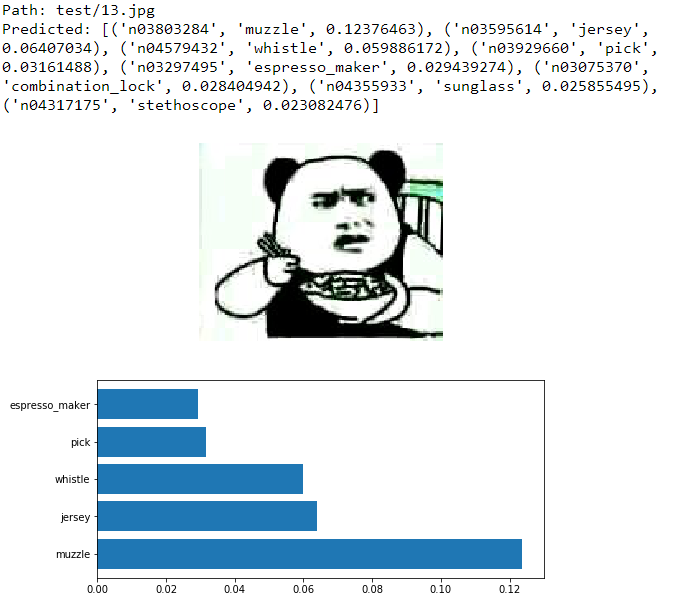
(ImageNet全1000分类见参考文献)
这里有一个坑是,直接在代码里调网络模型,下载速度可能会很慢(尤其VGG实在是太大了),所以可以手动下载好然后放在存储目录中:Linux路径~/.keras/models,Win路径C:\Users\老潘.keras\models,下载链接在参考文献中。
三、自动分类
到这里其实就已经成送分题了,直接把对应图片按照最高的类别概率放进不同的文件夹就行了。重点是关注一下准确度,由于没有标注好的数据直接做测试集,所以就自己用眼睛看来判断吧。
Python实现拷贝文件操作,将img_path指定的文件移动到done文件夹下,命名为13.jpg:
import shutil
new_path = 'done/13.jpg';
path = shutil.copy(img_path, new_path);
用Python遍历目录下的文件:
import os
result = []; #所有的文件的路径
for maindir, subdir, file_name_list in os.walk('test/'):
print("1:", maindir); #当前目录
print("2:", subdir); #当前目录下的所有目录
print("3:", file_name_list); #当前目录下的所有文件名
for filename in file_name_list:
apath = os.path.join(maindir, filename);#合并成一个完整路径
result.append(apath);
到这里基本所有需要的模块都准备完毕了,交给实习生去整合一下代码就可以使用了。
#-*- coding: utf-8 -*-
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil
model = ResNet50(weights='imagenet', include_top=True);
testing_dir = '火车/'; #存放待分类图片的路径
done_dir = 'done/'; #分类完毕的图片存放路径
temp_dir = 'temp/'; #未进入指定分类的图片,以免漏选
target_list = ['steam_locomotive', 'passenger_car', 'freight_car', 'electric_locomotive','bullet_train']; #指定挑出来的分类名称
for maindir, subdir, file_name_list in os.walk(testing_dir):
print("testing directory:", maindir); #当前目录
print("file list:", file_name_list); #当前目录下的所有文件名
for file in file_name_list:
img_path = maindir + file;
img = image.load_img(img_path, target_size=(224, 224));
x = image.img_to_array(img);
x = np.expand_dims(x, axis=0);
x = preprocess_input(x);
preds = model.predict(x);
if decode_predictions(preds)[0][0][1] in target_list:
new_path = done_dir + file;
path = shutil.copy(img_path, new_path);
print('select: ' + path);
else:
new_path = temp_dir + file;
path = shutil.copy(img_path, new_path);
print('out: ' + path);
准确度不是特别高,因为老潘发现这个图片竟然被分类成了货车,图片里明明是空铁道
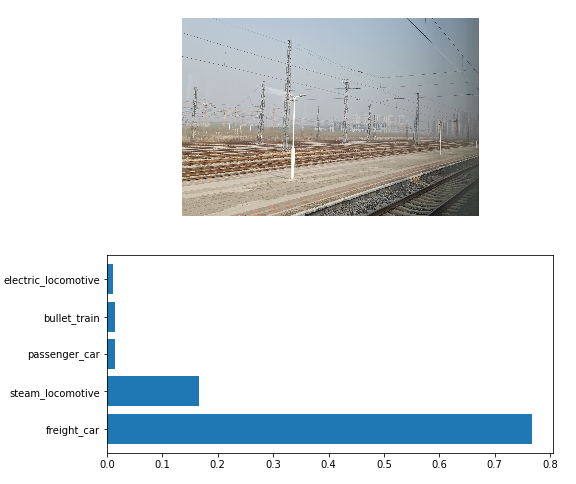
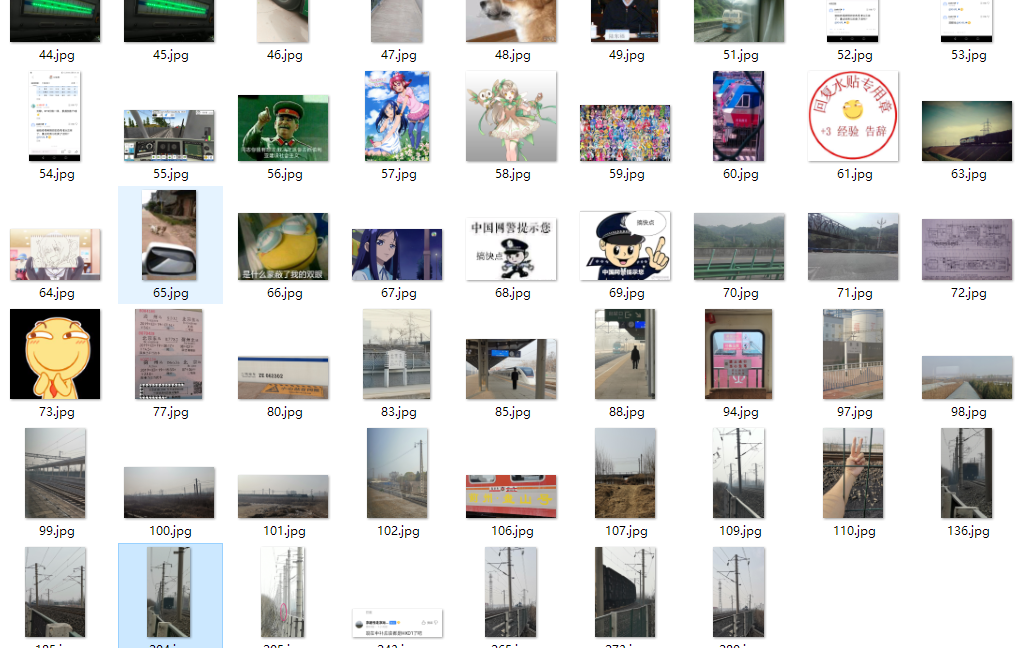
表情包和灌水图倒是都剔出去了,不过也有一两个由于特征确实不明显于是被遗漏没有被识别的:
四、校花识别
之所以这次真的讲了校花识别,是因为老潘良心发现不能当标题党ImageNet对识别人脸来说是无力的,上面那种方法只限于识别除人脸之外的物品,想分出人类/身体/美女的脸是不行的。所以针对识别照片中有没有人的需求,要用别的方法来操作。
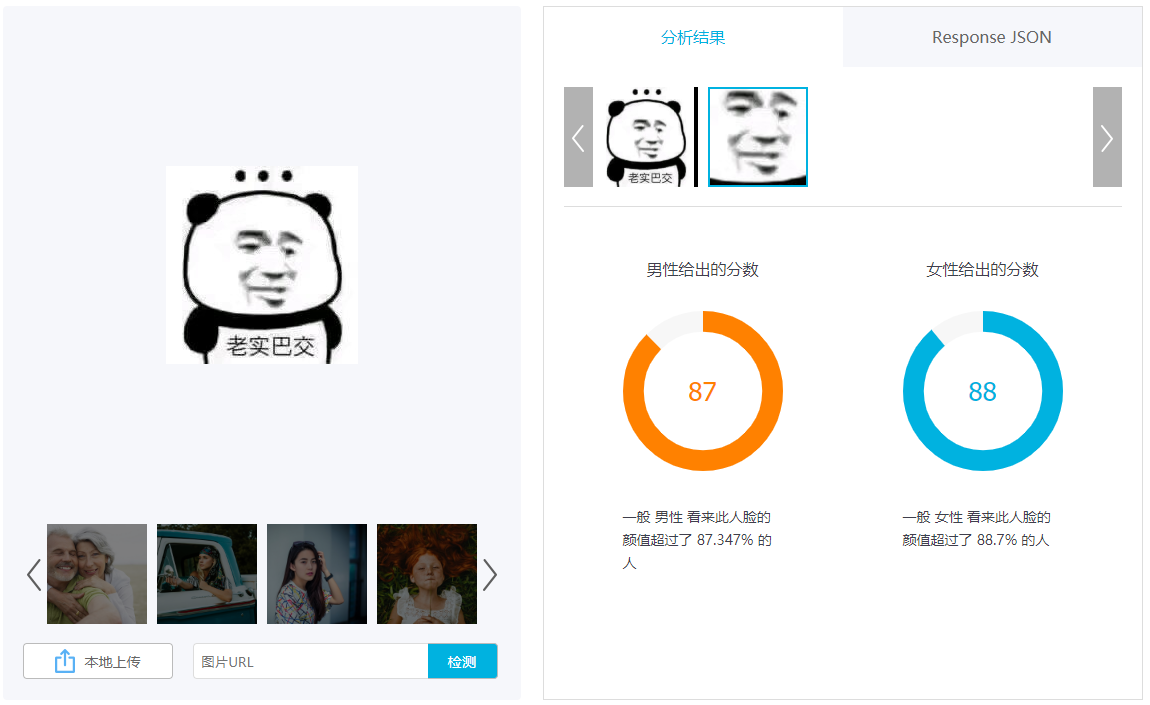
Face++上面有现成的API可以调用,注册一个账号可以获得使用一个免费试用的API接口,在官网上有很多应用场景,打开页面就可以直接体验一下,感觉效果好的话就可以用API接口在自己程序里直接调用,例如下面的在线测颜值打分:
关于API的应用,老潘在猎奇 | Python+ADB实现自动点赞和抽奖检测里面用到了百度的文本识别。
在Python中调用Face++的API方法如下:
import requests
from json import JSONDecoder
from PIL import Image
#HumanBodyDetect API(V1)
http_url = "https://api-cn.faceplusplus.com/humanbodypp/v1/detect"
file_path = "test/901.jpg"
temp_path = "temp/"
data = {"api_key": "老潘家的潘老师",
"api_secret": "Diverting_Pan",
"return_attributes": "gender"}
img = Image.open(file_path).convert('RGB').resize((512, 512), Image.BILINEAR) #API要求图片<2M或<1024*1024,而且色彩模式需要RGB
img.save(temp_path + "human_temp.jpg") #压缩后的图片缓存一下
files = {"image_file": open(temp_path + "human_temp.jpg", "rb")} #以二进制读入图像
response = requests.post(http_url, data=data, files=files) #POST上传
data里各个参数的作用可以在https://console.faceplusplus.com.cn/documents/4888383找到。这个API会返回图片中人物的性别的概率,所以可以根据有无此参数和此参数的值来筛选需要的图片。
若识别成功照片中有人,则将这个人的范围坐标、性别、穿衣颜色等信息包含在返回的信息里,如果没识别到有人则没有这些信息。通过读取返回的值,提取关键字段筛选有用的照片,以挑出有女性的照片为例:
req_con = response.content.decode('utf-8')
req_dict = JSONDecoder().decode(req_con) #解码成字典格式
if len(req_dict['humanbodies']): #如果图片中没有识别到人体则['attributes']['gender']['female']都不存在
ifreq_dict['humanbodies'][0]['attributes']['gender']['female'] > req_dict['humanbodies'][0]['attributes']['gender']['male']:
print("Female")
else:
print("Not Female")
else:
print("Not Female")
基本部件都准备完毕了,实习生可以再来加一下班了:(完整代码见GitHub)
#-*- coding: utf-8 -*-
import requests
from json import JSONDecoder
from PIL import Image
import os
import shutil
import time
http_url = "https://api-cn.faceplusplus.com/humanbodypp/v1/detect"
data = {"api_key": "_xdd7OMPd5rsHSsqwNaFTi-j-U_4T2HG",
"api_secret": "fnGuZLo26p2vn0MWh6MCRgIdg5p_sESp",
"return_attributes": "gender"}
#HumanBodyDetect API(V1)
testing_dir = '校花/';
done_path = 'done/';
temp_path = 'temp/';
for maindir, subdir, file_name_list in os.walk(testing_dir):
print("testing directory:", maindir); #当前目录
print("file list:", file_name_list); #当前目录下的所有文件名
for file in file_name_list:
file_path = maindir + file;
img = Image.open(file_path).convert('RGB').resize((512,512), Image.BILINEAR)
img.save(temp_path + "human_temp.jpg")
files = {"image_file":open(temp_path + "human_temp.jpg", "rb")}
response = requests.post(http_url,data=data, files=files)
req_con = response.content.decode('utf-8')
req_dict = JSONDecoder().decode(req_con)
if len(req_dict['humanbodies']):
if req_dict['humanbodies'][0]['attributes']['gender']['female'] >req_dict['humanbodies'][0]['attributes']['gender']['male']:
new_path = done_path + file;
path = shutil.copy(file_path, new_path);
print('select: ' + path);
else:
new_path = temp_path + file;
path = shutil.copy(file_path, new_path);
print('out: ' + path);
else:
new_path = temp_path + file;
path = shutil.copy(file_path, new_path);
print('out: ' + path);
time.sleep(1) #如果循环速度太快会被服务器断掉链接
有一个改进策略是记录下最近一次成功操作的文件,如果发现网络连接发生错误或者被服务器断掉连接就自动断点续传,<del不过老潘懒得做了可以留作课后作业交给各位想试着做的同学。
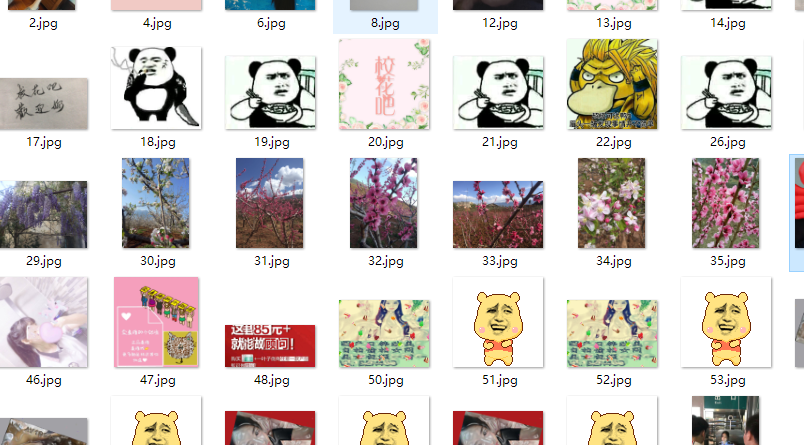
分类结果准确度不是特别高,不过也分出了大部分的水图,个别图片由于人体特征不明显或者性别特征不明显导致了分类失败
五、总结
统计一下本次实验分类的情况
火车图片(ResNet50)总数 589
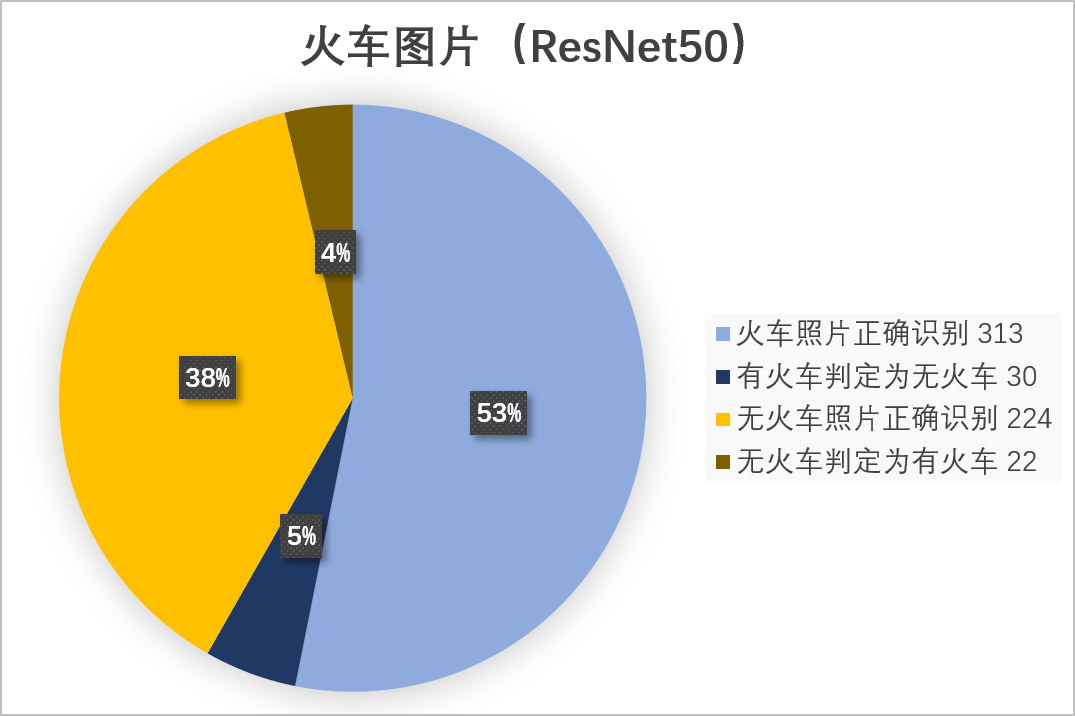
美女图片(Face++)总数 573
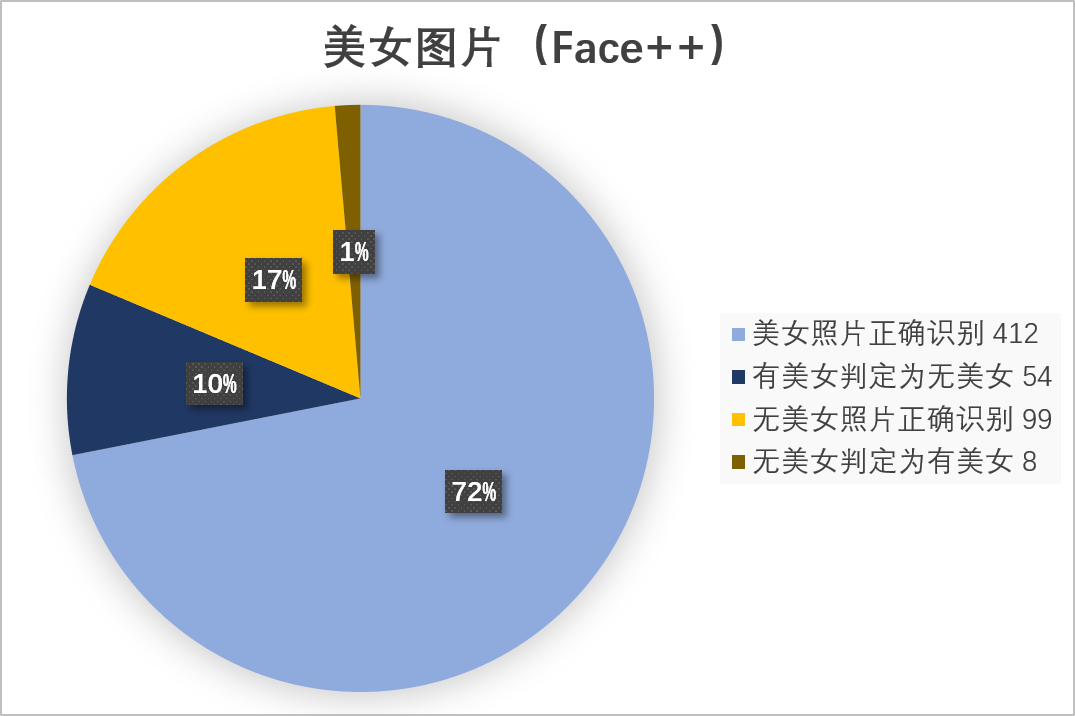
由于都是未加工的从网上抓的原生图片,所以只能依靠自己手动分类。而且很多图确实含混不清,比如在图片上只有一个火车车门,我把这类图也归结为有火车的类别了,依此标准来进行准确度的判别。不过从这个准确度看来,本次项目的两类自动分拣机,都有很大**调校(jiao)**的潜力。
从网上通过爬虫获取图片有一定几率导致图片结尾异常,从而导致程序读取图片出错
(OSError: image file is truncated (0 bytes not processed))
若遇到这种错误,删掉出错图像即可。可以添加一个检测图片读取成功的代码,不成功读取直接跳过(后记:可以用try/except)。老潘懒得做了留给大家作为课后作业。
六、参考文献
[1] keras中使用预训练模型进行图片分类:https://www.cnblogs.com/vactor/p/9813108.html
[2] Keras中模型 《th与tf的区别》、《notop的含义》:https://blog.csdn.net/elvirangel/article/details/88854612
[3] keras的基本用法(四)——Fine Tuning神经网络:https://blog.csdn.net/quincuntial/article/details/72896690
[4] 全连接层有何作用?https://www.cnblogs.com/Terrypython/p/11147665.html
[5] 实战 迁移学习 VGG19、ResNet50、InceptionV3 实践 猫狗大战 问题:https://blog.csdn.net/pengdali/article/details/79050662
[6] keras离线下载模型的存储位置:https://www.jianshu.com/p/0a4ba12df520
[7] keras提供的所有模型下载地址:https://github.com/fchollet/deep-learning-models/releases
[8] 使用keras加载vgg16等模型权重文件失败的解决办法和模型.h5文件网盘下载地址:https://blog.csdn.net/icurious/article/details/80077035
[9] VGG16学习笔记:https://blog.csdn.net/dta0502/article/details/79654931
[10] VGG16学习笔记:https://www.cnblogs.com/lfri/p/10493408.html
[11] ResNet解析:https://blog.csdn.net/lanran2/article/details/79057994
[12] Python 列表推导式:https://www.runoob.com/note/15802
[13] Python——使用matplotlib绘制柱状图:https://www.cnblogs.com/decode1234/p/8535638.html
[14] ImageNet图像库1000个类别名称(中文注释不断更新):https://blog.csdn.net/weixin_41770169/article/details/80482942
[15] python3之shutil高级文件操作:https://www.cnblogs.com/zhangxinqi/p/8038479.html
[16] Python遍历指定目录下的所有文件以及文件的过滤:https://blog.csdn.net/douyaoxin_126/article/details/88638359
[17]人工智能,机器学习,神经网络,深度学习的关系:https://blog.csdn.net/lemonade_117/article/details/82668084
[18] PYTHON 3 调用face++API代码(简单易懂):https://blog.csdn.net/qq_41122796/article/details/79945873
[19]文档中心/HumanBody Detect API(V1):https://console.faceplusplus.com.cn/documents/10071565
[20] Python3 字典:https://www.runoob.com/python3/python3-dictionary.html
[21]利用python PIL库进行图像模式的转换:https://www.jianshu.com/p/2e9539bdc307
[22] Python程序中PIL Image "image file is truncated"问题分析与解决:https://blog.csdn.net/scool_winter/article/details/89426509