进阶 | 利用Python开挂式获取网络资源——以搜集贴吧图片为例

这算是系列作了吗?反正今天主要内容仍旧是围绕利用互联网获取信息。这次内容是讲解Python的起家功能:爬虫,用百度贴吧的众多图片贴来入门爬虫思想和测试爬虫效果(怎么和百度干上了?)
至于为什么叫爬虫不叫爬狗爬猫,这个来源已不可考。可能是这种行为很像一个虫子满屋到处无死角爬?

摘 要
本项目以获取3000+来自百度贴吧的图片为目标,寓教于乐,注重实践,通过实际案例和详细步骤操作,揭露了挂逼在网上获取大量美女照片骗取宅男钱财的幕后操作。
绪 论
如果你在2019年5月12日晚上得知,百度贴吧药丸,你混迹的贴吧里的几百个精华帖的几千副世界水准摄影作品马上要灰飞烟灭。你打算抢救,把这些图都下载到你的硬盘里。显然,一个一个的右键另存为是不可行的,多找几个人也没人愿意鸟你。怎么办呢?
这时我们的老朋友Python登场,带着他的好兄弟美容养颜毒鸡汤(BeautifulSoup),可以帮助你一边听音乐一边打游戏顺便吃个外卖,随手完成这个轻松?的工作。

BeautifulSoup是Python的一个库,专职网络爬虫。爬虫的主要用途就是收集网络里大量、重复、繁杂的数据。比如说,贴吧里几千副世界水准的摄影作品,虽然数量很多,但是都集中在贴吧,而且也有一些规律性的指标帮助我们定位到图片的下载链接上,这就为实现下载图片自动化提供了契机。找规律的方法将在下文阐述。
接下来就是捡肥皂表演时间了,本篇所用程序基于CSDN博主‘Python编程爬虫工程师’的文章《这是一个Python百度爬虫,采集贴吧大佬们发布的所有美女照片》改编且详细分析讲解。请各位同学注意力从美女照片上移开认真听讲。
一、让老朋友开始工作
BeautifulSoup(下文简称BS)可以像浏览器那样,打开页面,下载文件,只是不通过鼠标点击,不通过屏幕显示画面,所有的动作统统通过代码做完。有点像之前讲的ADB。
BS可以接收一个URL链接(网址链接),并且解析链接背后的内容。如果把他接收的内容输出成文本,就能看见HTML代码。
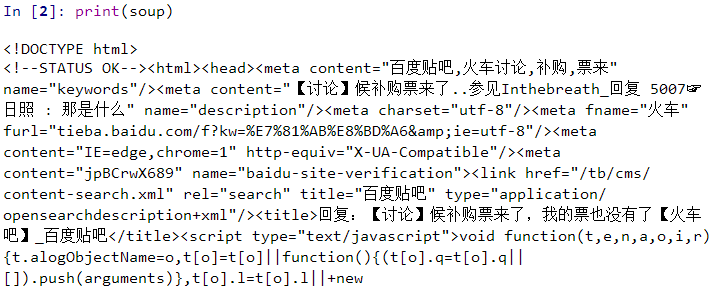
我们后面获取图片下载链接,需要依赖这个功能。而需要BS打开哪些链接,也需要事先做好调查,写好链接传送给BS。好在这些链接都有一些规律可循。下面来讲一讲如何找规律。
二、找规律
2.1 图片链接的规律
下载图片的过程很简单,拿到一个图片的下载链接,放进下载器,或交给BS就能存到你的电脑。获取下载链接有两种方法。一是右键,选择另存为,这属于浏览器直接捕获链接并且执行下载。但是这种方法以低效且费鼠标而为人所唾弃。二是在网页的HTML代码中找到图片的链接,收集很多这样的链接之后批量下载。如果你使用Google,在图片上直接右键,并且点击“检查”,你就可以打开装逼界面。
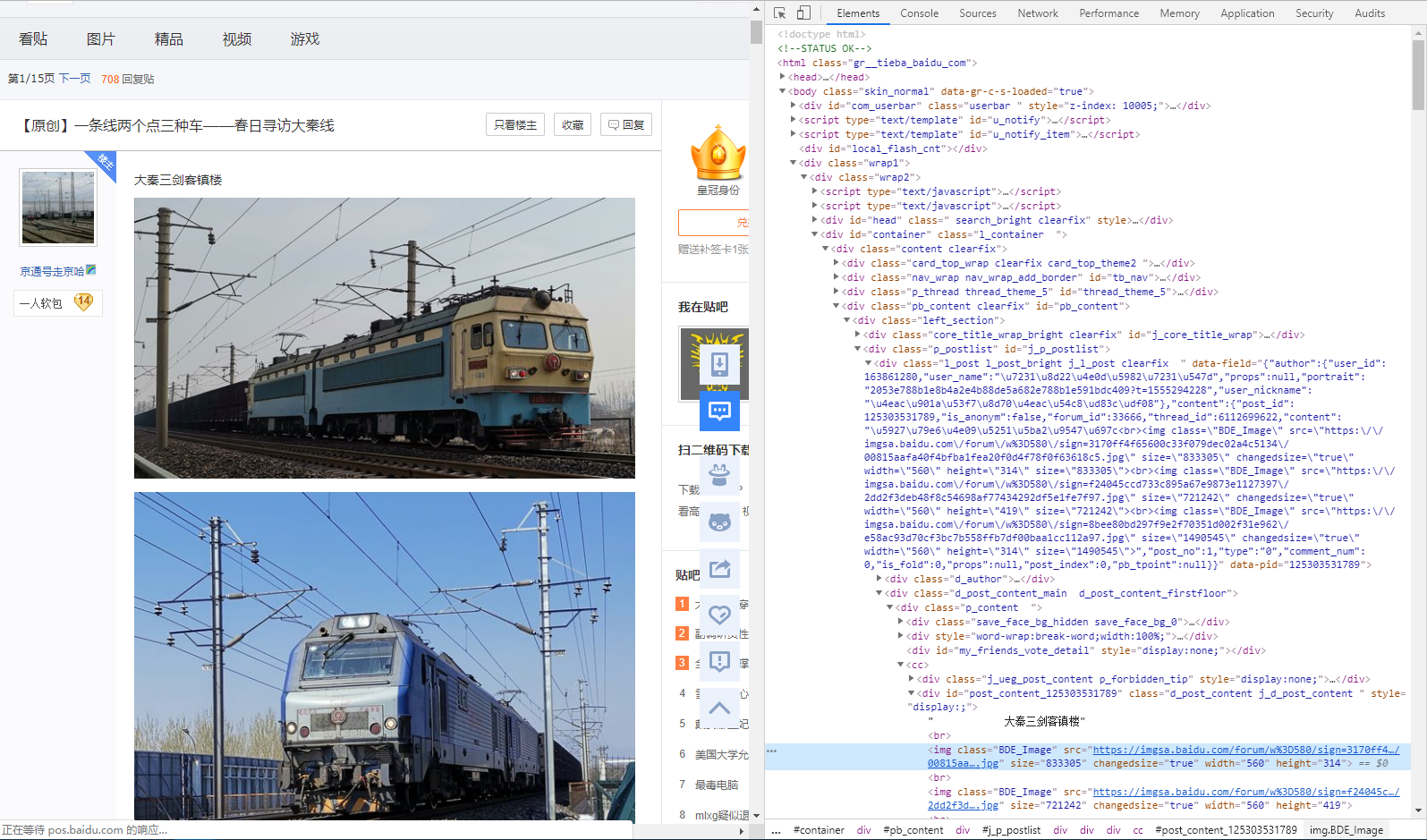
注意,在右边的代码里,有一行被标记的代码,那就是刚刚检查的图片链接。如果直接点击那个链接,就可以单独打开这个图片,也可以放进下载器下载。还会看到这页其他图片的链接,指着他,对应的图片也会被标记,指着链接,图片的缩略图也能显示。
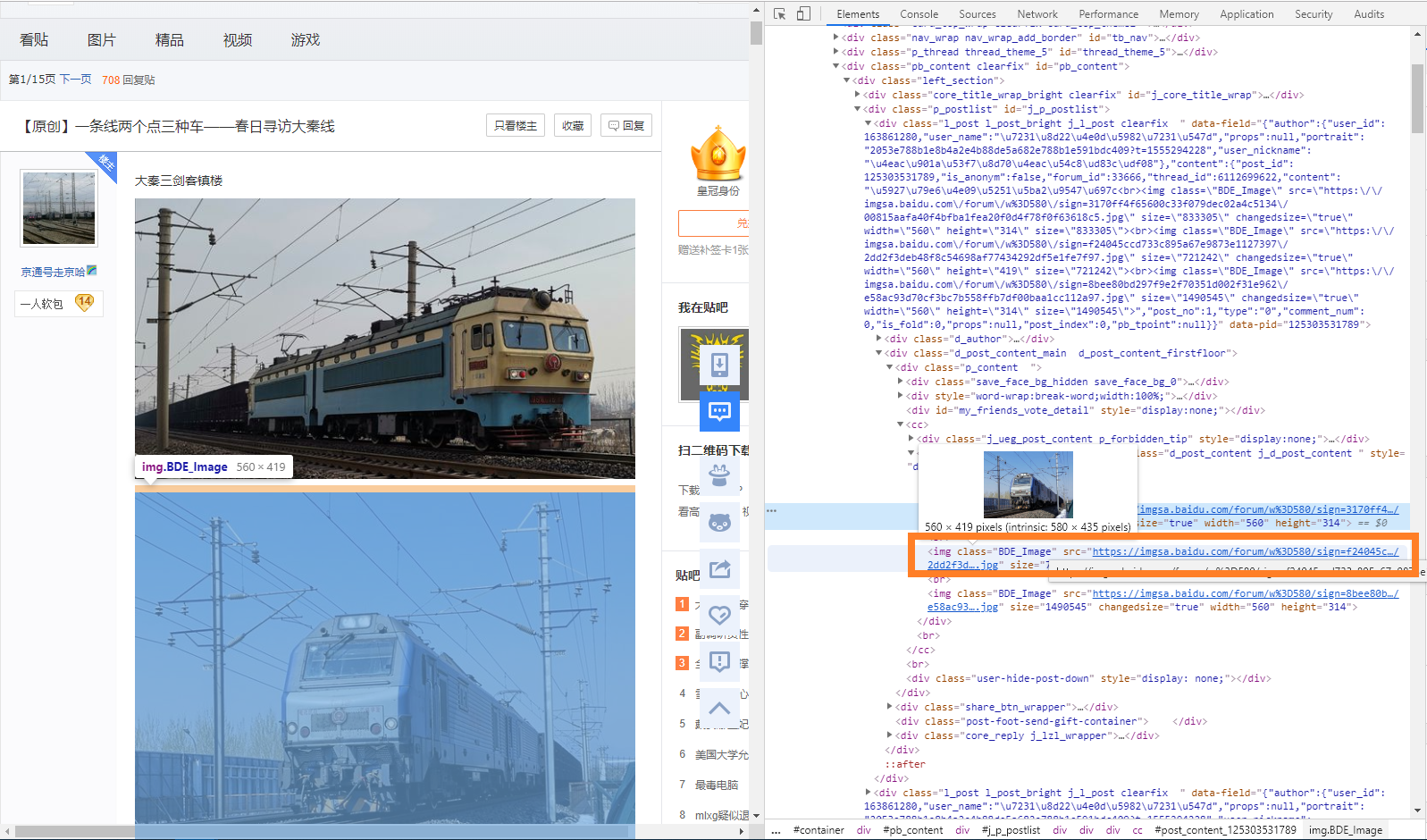
这时候观察一下代码,可以看到图片的下载链接都放在<img>的HTML标签里,这个标签都有一个class值BDE_Image,而且链接的属性名都是src。
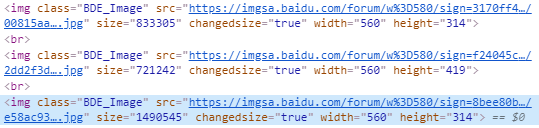
所以,任务一下子简单了起来,如果能搞一个自动开网页,自动找到“BDE_Image”的<img>标签,把这里的src给下载器。就完成了图片的存储工作,根本不需要点鼠标。
res = session.get(each)
soup = BeautifulSoup(res.text, 'html.parser') #关于打开网页,下文会讲
img_urls = soup.find_all('img', class_='BDE_Image') #这里会以列表结构存下所有的img标签内容
for img in img_urls:
thumbnail = img.attrs['src'] #循环依次抽取图片链接
2.2 开网页
上面已经找到了图片的存放规律。现在问题就上升到如何打开这些网页?潘老师这么懒,肯定不会手动打开这些网页交给Python去弄。实际上,网页也是有分布规律的。
2.2.1 贴吧操作
以贴吧为例,每个贴吧虽然名字都不同,但是网站却有很强规律性,一个贴吧链接示例(还有一些其他的参数但是对爬取工作并没有作用):
https://tieba.baidu.com/f?kw=火车&pn=0
显然,贴吧名是火车,pn是页码,每翻一页,页码加50,原因是一页显示50条帖子。找到了规律,就可以交给程序自动操作了。
tiezi_url = "http://tieba.baidu.com/f?kw=" + keyword + "&pn=" + str(i * 50)
不过,我想要精品贴里面的图,其他垃圾帖子里可能很多都是广告或者水楼的表情包,点进精品贴,看到链接会发生变化:
https://tieba.baidu.com/f?kw=火车&tab=good&pn=0
只是在参数里多了一个&tab=good的参数,那就对应修改上面代码多一个参数即可:
tiezi_url = "http://tieba.baidu.com/f?kw=" + keyword + "&tab=good&pn=" + str(i * 50)
贴吧里的帖子一共有几页?pn后面这个数要到几才能停下来?
因为刚刚也说了,贴吧一页显示50条帖子,所以我们使用总帖子数÷50,得到的数向上取整,这个数就是最后一页的页码了,使用(页码-1)*50(因为起始pn值是0),得到的就是pn的最终数字。于是新的问题是,如何获取帖子数,如果有同学对如何向上取整有疑问请放学罚抄《Python入门到放弃》一百遍。
观察一下贴吧,潘老师在页面角落发现了共有精品数2075个字样:

对数字“检查”,于是发现这个数字在class="red_text"的<span>标签下,由于这个文字是直接在文本区域,不属于任何一个属性,所以就直接利用find().text获得文本。获得这个数字之后做除法即可。
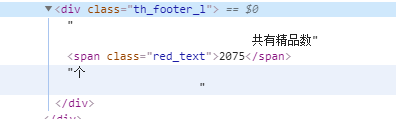
total_num = soup.find('span', class_='red_text').text
total_num = int(total_num.replace(',', '')) #原程序识别总帖子数时,需要删掉数中间的逗号分隔符
page_size = 50
total_page = math.ceil(total_num / page_size)
for i in range(0, total_page):
#这样会抓取所有的精品贴,如果嫌多可以改total_page为小一点的数字
#另外,Python的for循环最后一次是range里的上限值-1
tiezi_url = "http://tieba.baidu.com/f?kw=" + keyword + "&tab=good&cid=0&pn=" + str(i * 50)
不要着急,潘老师应该测试一下最后一页的pn是不是=(向上取整(帖子数/50)-1)*50,免得打脸。
大呼三声:百度老狗!以解锁下文。
2.2.2 帖子操作
分析完贴吧的链接规律,再看看每个帖子的链接的规律。这是一个帖子的链接示例:
https://tieba.baidu.com/p/6112699622
非常直接了,不同帖子就是通过最后那串数区分开的。但是这不像贴吧名,这数是没什么实际意义的,怎么获取呢?
这就得分析HTML代码,找到每条帖子对应的这串数字。和找图片链接类似,在某条帖子的标题上,点击右键,检查,一下子就出来了。
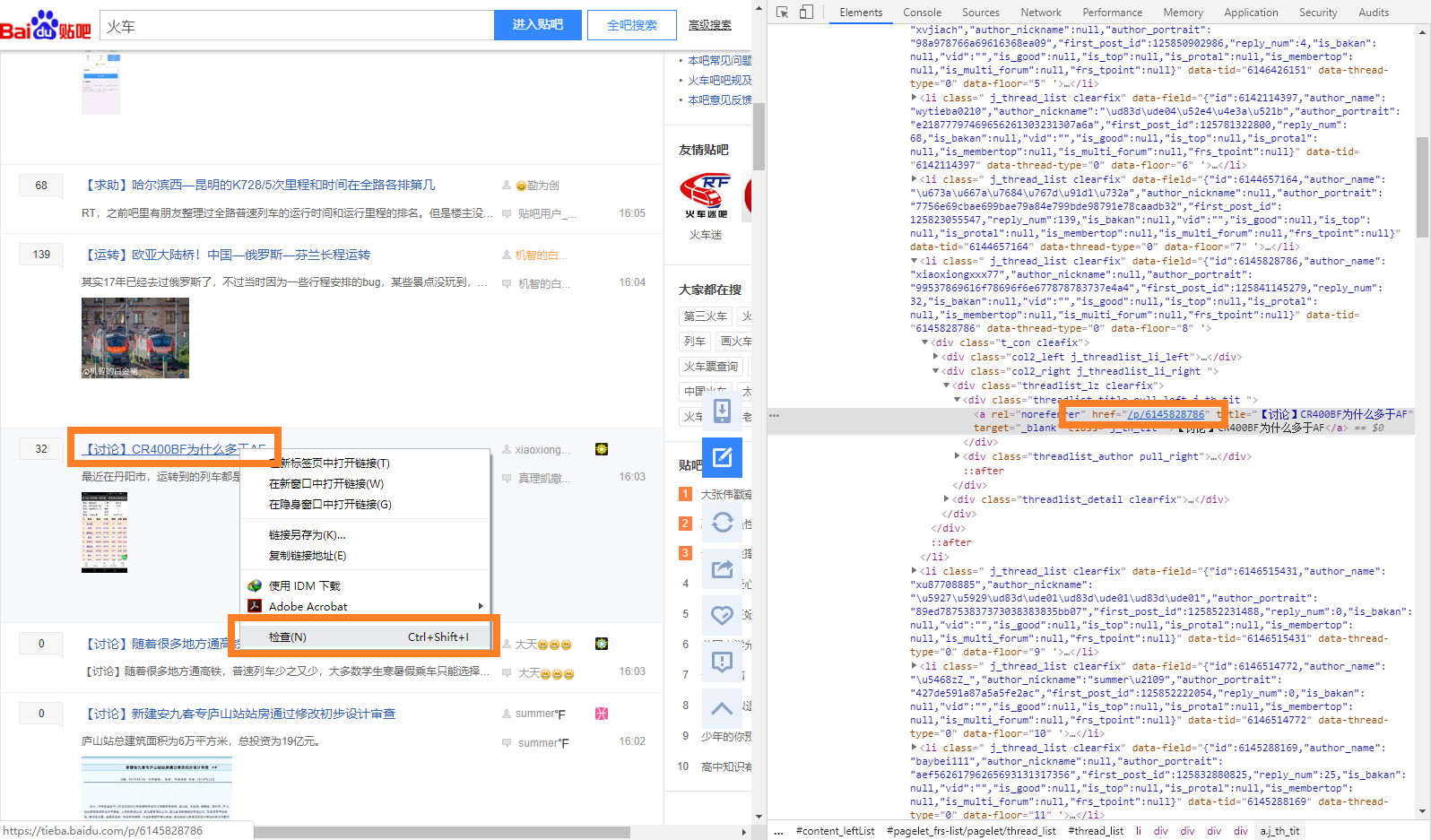
提取的过程也类似,可以看到这串字符在class="j_th_tit"的<a>标签中,属性名为href,把这串抽出来,接在http://tieba.baidu.com后面,就能获得一个帖子的真实有效链接了。
static_tiezi_urls.append("http://tieba.baidu.com" + each.attrs['href'])
但是还有一点问题。帖子是会翻页的。翻页会引起链接怎样的变化呢?观察下面的这个帖子在第二页时的链接:
https://tieba.baidu.com/p/6112699622?pn=2
在最后多了一个?pn=2的参数。其实现在你也应该大致了解HTML的套路了。用一些不同的参数值来区分相似页面的不同状态,所以说网络爬虫是非常高效的。
于是只需要打开一个帖子之后,在链接后面加上这个参数,并且循环pn=x后面的这个数字,一直到最后一页,浏览完整个帖子。
怎么判断有没有到最后页呢?潘老师的做法是,检测页面有没有下一页的按钮,没有这个按钮,必定后面没有页了,就该结束了。检测按钮又需要分析HTML代码。在一个有“下一页”按钮的帖子里,“检查”这个按钮,
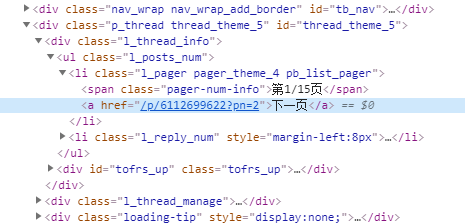
哎,不好搞哎,这个下一页不像刚才那个帖子数,不在标签里,也不是什么属性,重要的是这标签也没有class,BS的find()怕是find不到。不过可以直接对HTML代码本身下手。直接检测页面代码里有没有“下一页”三个字不太稳妥,因为HTML正文的文本里可能也会有这仨字。不过,如果检测页面有没有>下一页</a>这一串,应该就能稳一些了吧。
while(true):
if '>下一页</a>' in res.text:
page += 1
each = re.sub(r'\?pn(.*)?$', '', each)
each = each + '?pn=' + str(page)
else:
break
用了正则,因为上一页的链接尾部有?pn=2这样的页码,得删了旧的页码再写新页码。使用正则直接删除从链接里唯一的问号开始,到链接结束这中间的字符,之后再补上新的pn=x即可。
三、下载图片
潘老师使用这个博主的代码下载图片的时候发现了以下问题:原代码的从贴吧获取帖子链接的部分class_='j_th_tit '后面这个空格是不可以留的,因为原本的class名也不可能会出现空格,即使HTML代码里类名后面有个空格,那空格也不会安在class的名字后面,在Python代码里给这个属性加了空格去识别反而会导致识别不到。
上面那是个小问题因此程序不通导致潘老师调试10分钟算小问题吗,第二是帖子翻页的问题,按照原程序,只能打开帖子的第一页下载图片。固然美女贴通常只有在一楼有照骗楼下基本都是舔狗,我们需要追求程序的通用性,所以上一节的翻页爬虫是必需的。
潘老师还临时发现一个问题是帖子数量问题。原程序获取的是帖子数,帖子其实是俗称的“楼”,实际贴吧的文章量应该是主题数,主题数在贴吧的左下角,要捉这个数字才对。只能怪百度老狗自己都没搞清楚这乱七八糟的数字该怎么管理。
再一个是图片尺寸的问题。原贴直接从帖子页面获取图片链接,但是直接打开帖子,不管是显示还是下载,得到的都是压缩过的小图。必须点开图片才能获得高清大图。本着看美女就要看高清图的思想,潘老师决定拓展一下原程序的功能。让老朋友加加班,帮我们点进大图去下载。
例如打开一个图片帖子,不管你右键存图也好,获取下载链接存图也好,图就只有这么大:
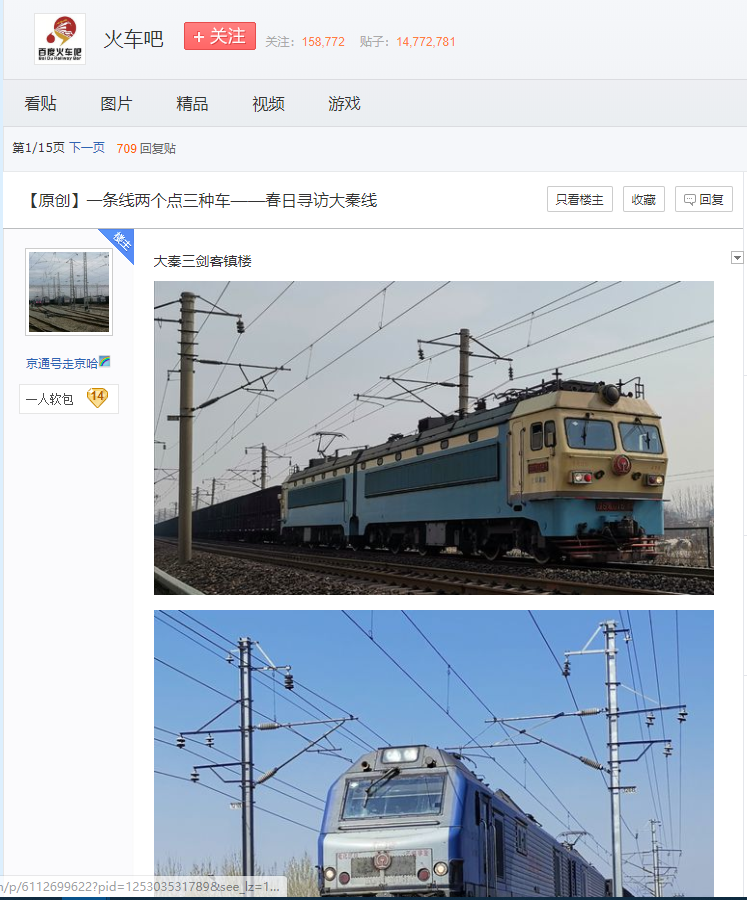
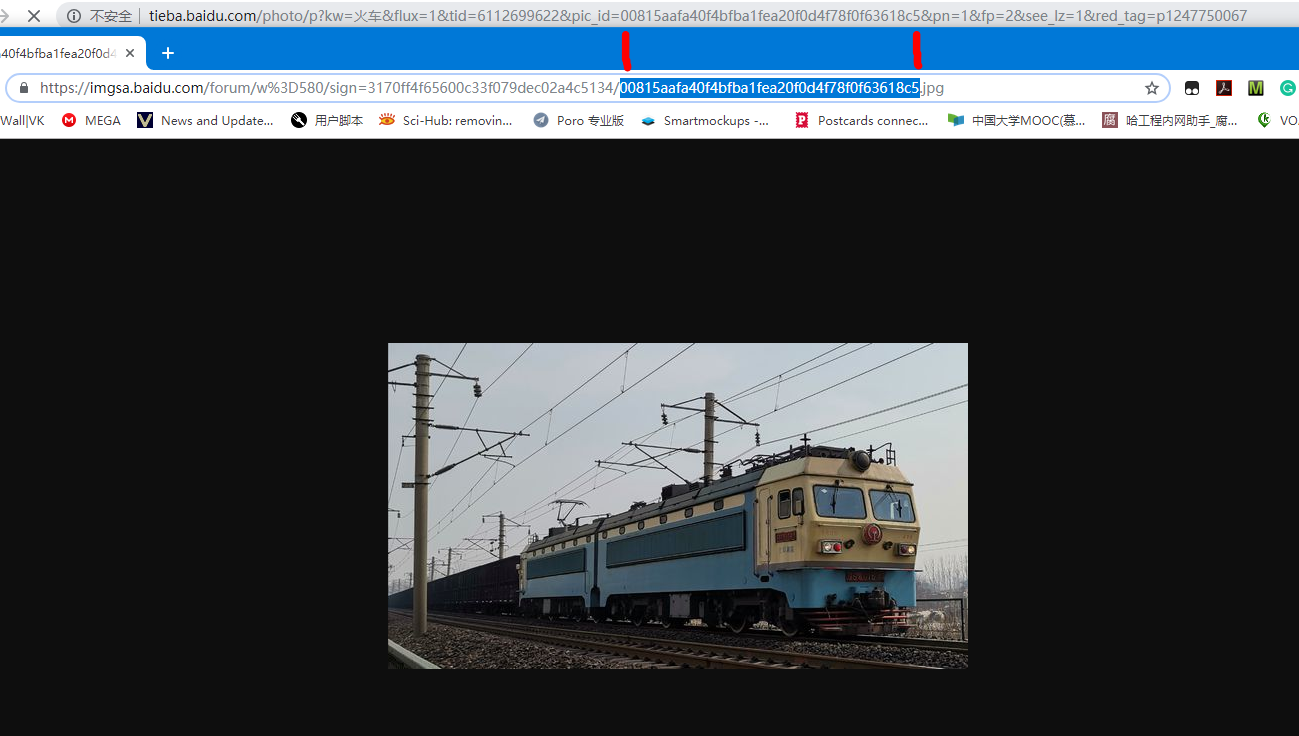
但点击一个图片之后,进入看图模式,存这个图就是高清大图惹:

思路很简单,照搬前面的做法基本就够用。由于没法从帖子直接获得看图模式的链接,所以就得观察这个页面的链接看看有什么规律。下面是两个不同帖子的不同图片的链接:
http://tieba.baidu.com/photo/p?kw=火车&flux=1&tid=6112699622&pic_id=00815aafa40f4bfba1fea20f0d4f78f0f63618c5&pn=1&fp=2&see_lz=1&red_tag=p1247750067
http://tieba.baidu.com/photo/p?kw=火车&flux=1&tid=6106875508&pic_id=f08d0cf3d7ca7bcb4276997eb0096b63f724a8d1&pn=1&fp=2&see_lz=1&red_tag=y1523450118
这个难度稍微大了点,毕竟到压轴题了啊。不过不慌。首先经过试验,&red_tag=不会影响对图片的加载,删除之。不同帖子,不同图片,都有一样的部分(标红):
http://tieba.baidu.com/photo/p?kw=火车&flux=1&tid=6106875508&pic_id=f08d0cf3d7ca7bcb4276997eb0096b63f724a8d1&pn=1&fp=2&see_lz=1
不同的只有&tid=和&pic_id=,这就非常简单了,tid就是这个帖子地址后面的那串数字,pic_id是在帖子里的小图片的下载链接的图片文件名。对比二者链接即可发现对应关系:
好的,进入大图页面后,把大图存下来即可。这里操作和2.1一致,在大图上右键检查,<img>标签下,class="image_original_original",src后面即为图片真实可用的链接了。

结果潘老师兴致勃勃以为这样可以获取美女高清大图的时候,百度老狗悄咪咪说

这么做是不行的。
潘老师发现这么做根本下载不来图。调试的时候发现,程序压根就没有获取到src链接。经过仔细确认是不是代码不小心多了少了点字母之后,潘老师发现
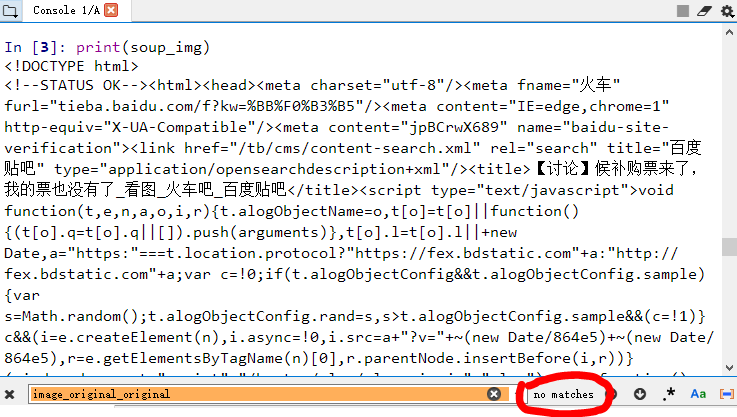
怎么页面里没有这个标签吗?那图片的链接藏在哪了?
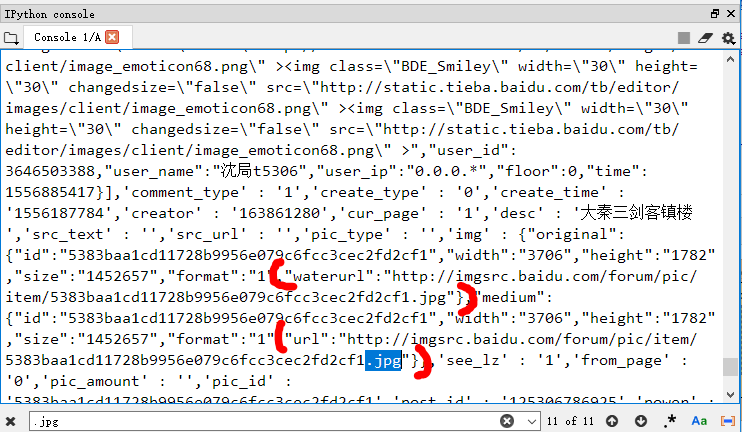
??所以说用浏览器和用BS打开的页面不一样??不过确认之后,这链接确实也是高清大图的链接。
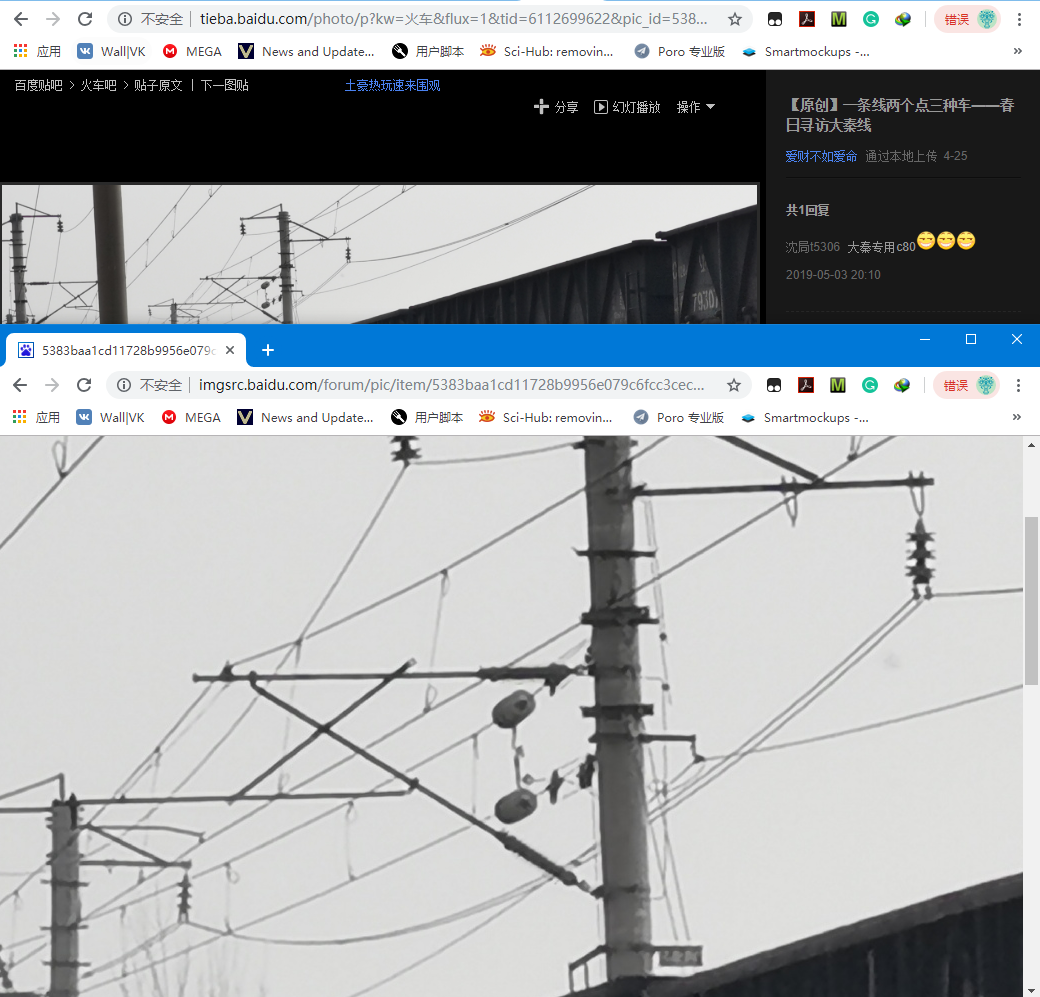
所以说,直接点击帖子里的图片进入大图模式,图并没有加载在网页里,猜测可能是有一个类似控件的东西在承载着显示图的功能,而这个控件没法被BS加载。
所以直接把接到的HTML转成文本,利用正则抽出图片URL。
res_img = session.get(high_img) #利用session模拟登陆后,加载网页
soup_img = BeautifulSoup(res_img.text, 'html.parser') #获取网页内容,html.parser解析
s = str(soup_img)
r = re.findall(r'(?<="waterurl":")(?![\w\W]*?"waterurl":").*(?="},"medium")', s)
high_img_urls = ''.join(r) #正则返回一个列表,需要将他展开成字符串
四、最终演示
基本已经完工了,如果没有意外的话就可以交给实习程序员让他去完善代码了。原代码说不登陆没法正常用,不过潘老师试验并不影响。顺带一提,Python模拟登陆通过requests库的session完成。

运行,输入贴吧名字,回车即可使用。
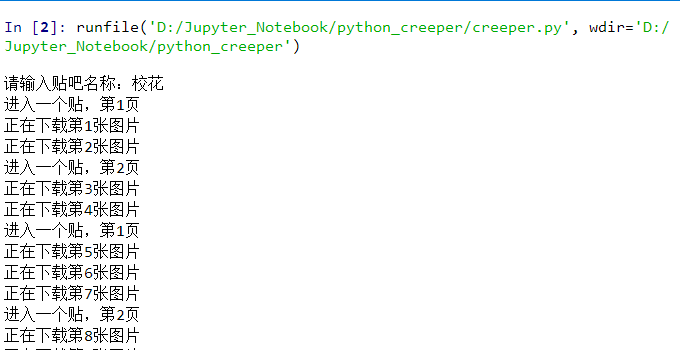
哎呀,手滑了呀,我是想输入“火车”,什么垃圾输入法。搜狗果然是比百度更老的狗。
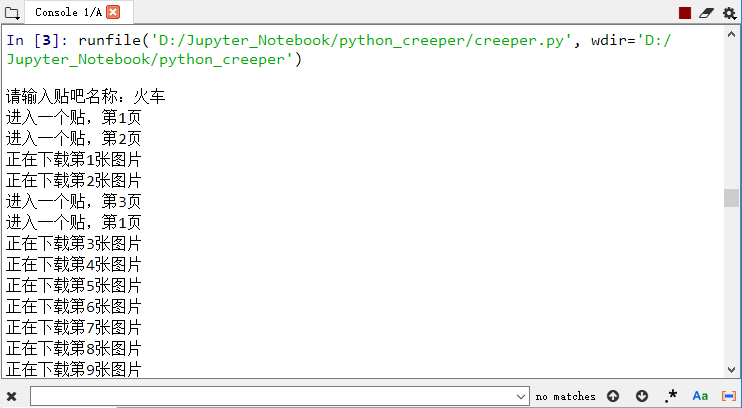
嗯,来看看都抓了些什么图出来。
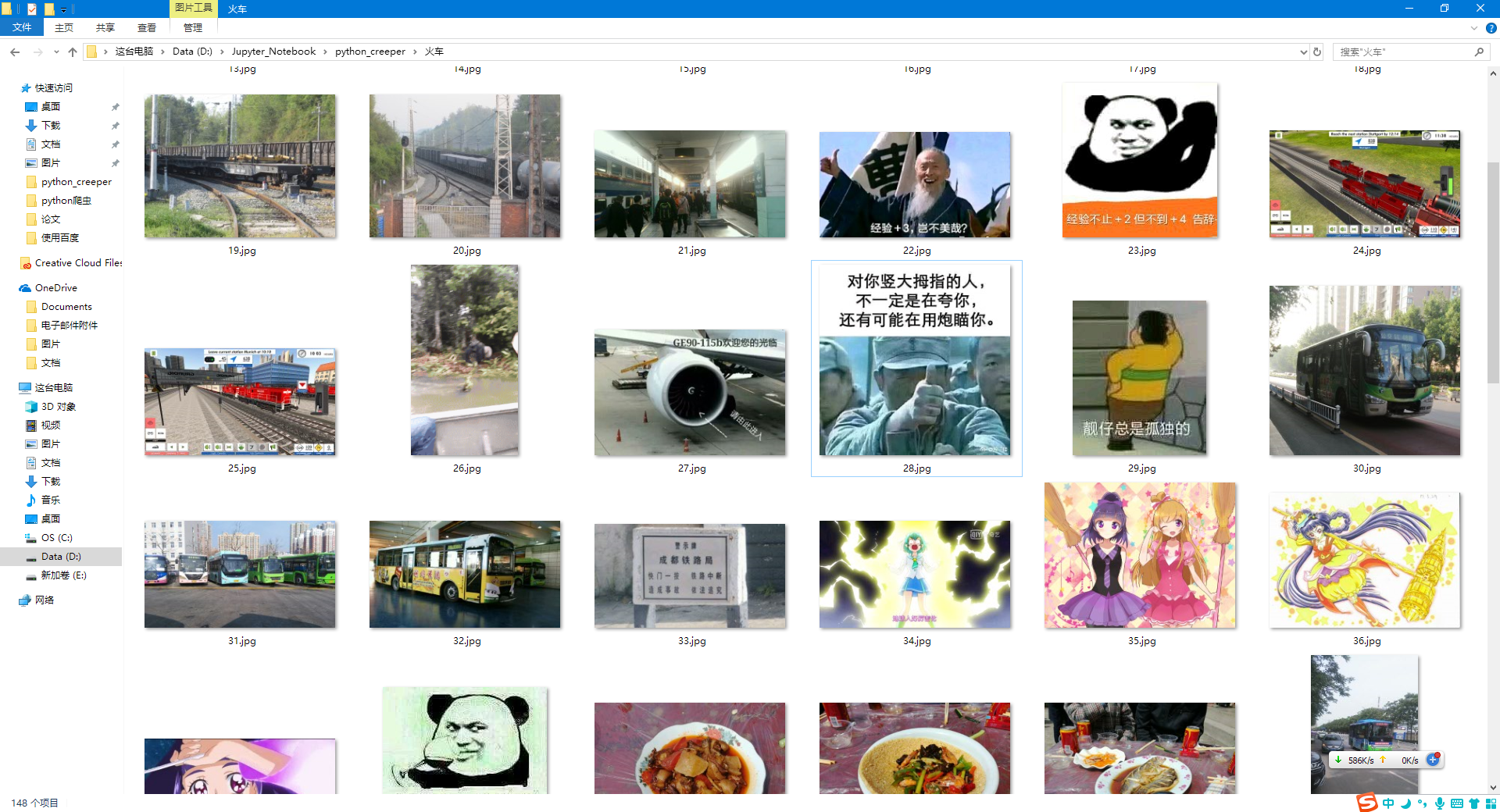
看来是不小心抓了一个大水贴啊。往后看看正经图片,看看清晰度如何。
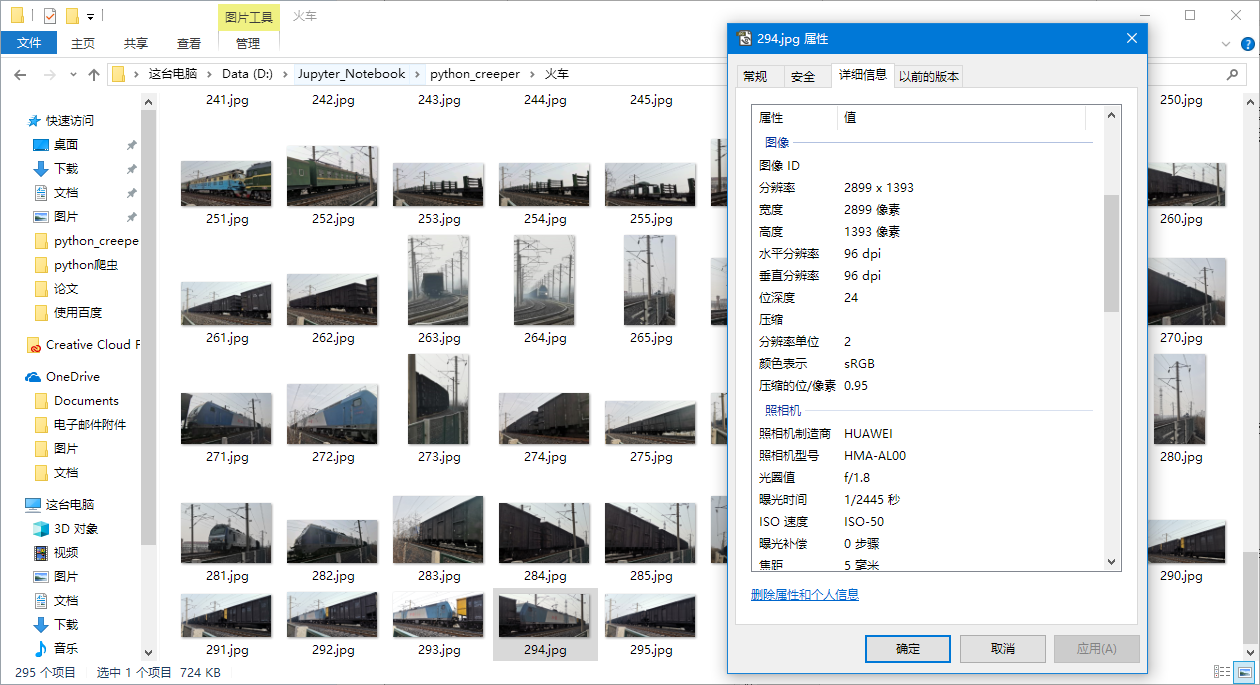
不错,连EXIF信息都有。所以说啊各位同学,记得关闭手机拍照带GPS的功能,不然人家真的是顺着网线找到你。

五、常见报错解决指南
这种短时间内开发出来的程序,必定会有不成熟的地方。潘老师自己测试的时候发现了以下可能发生的错误,并附上解决方法。
5.1 连接失败
如果使用时突然报错:
ConnectionError: ('Connection aborted.', TimeoutError(10060, '由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。', None, 10060, None))
这种情况多半是百度发现你在干坏事封了你的号是你的网速不太好,也许是因为室友不小心剪断了你的网线,或者在偷用热点下载什么见不得人的影片造成的。
如果使用时突然报错:
ConnectionError: ('Connection aborted.', ConnectionAbortedError(10053, '你的主机中的软件中止了一个已建立的连接。', None, 10053, None))
这种情况是你的网络状态不稳定,一般是因为室友不小心剪断了你的网线造成的。
5.2 图片下载错误
极特殊情况下会出现某个帖子里的图片下载下来后文件异常,一般该错误具有帖子集中性。经潘老师反复检测,图片链接,下载信道均无明显异常或干扰。猜测是由于百度老狗的神秘力量造成的。
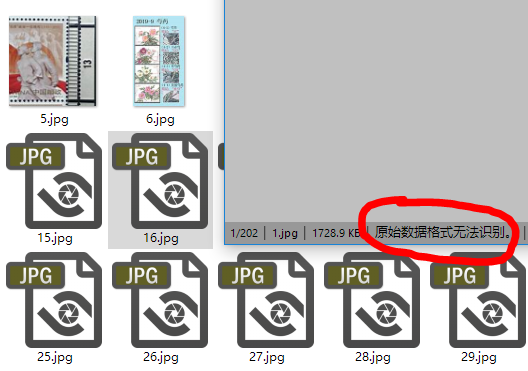
综上,程序出错都是你自己或者百度的原因,和潘老师没有一点儿关系。
参考文献
[1] 这是一个Python百度爬虫,采集贴吧大佬们发布的所有美女照片. https://blog.csdn.net/qq_41841569/article/details/83792663
[2] python str,list,tuple转换. https://www.cnblogs.com/nopnog/p/7066578.html
[3] 使用正则匹配最后一个字符串. https://blog.csdn.net/qq_18703313/article/details/78794364
[4] 正则表达式在线测试.https://c.runoob.com/front-end/854
[5] Python中BeautifulSoup库的用法. https://blog.csdn.net/qq_21933615/article/details/81171951
[6] 火车吧-百度贴吧. https://tieba.baidu.com/f?kw=%E7%81%AB%E8%BD%A6&ie=utf-8&tab=good
附录1
以下是潘老师进行整个实验所用的程序全文。报错缺module的话先pip安装对应的库。环境Python3.6。或者前往GitHub下载完整项目,非常神奇的是,这个项目已经送去北极的冰库了,老潘也不知道为什么。
# -*- coding: utf-8 -*-
import requests, math, os.path, re
from bs4 import BeautifulSoup
# 模拟登陆的方法
def login():
# 登录的用户名
username = '老潘家的潘老师'
# 登录的密码
password = 'divertingPan'
# 登录所需的参数
login_data = {
'username': username,
'password': password,
'u': 'https://passport.baidu.com',
'tpl': 'pp',
'staticpage': 'https://passport.baidu.com/static/passpc-account/html/v3Jump.html',
'isPhone': 'false',
'charset': 'utf-8',
'callback': 'parent.bd_pcbs_ra48vi'
}
# 构造所需的headers
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"
}
# 登录的url
baidu_loginurl = "https://passport.baidu.com/v2/api/?login"
# 创建session
session = requests.session()
# 模拟登陆
session.post(baidu_loginurl, login_data, headers=headers)
# 创建session
return session
# 获取总页数的方法
def get_total_page(url, session):
# 获取网页内容
res = session.get(url)
# 解析出帖子总数
soup = BeautifulSoup(res.text, 'html.parser')
tiezi_total_num = soup.find('span', class_='red_text').text
tiezi_total_num = int(tiezi_total_num.replace(',', ''))
# 贴吧默认每页50条帖子
page_size = 50
# 计算出总页数
total_page = math.ceil(tiezi_total_num / page_size)
return total_page
# 获取帖子url列表的方法
def get_tiezi_url_list(total_page, url, session):
#下面循环几次就是抓几页的帖子
#是贴吧的翻页,不是帖子的翻页,帖子都会从一楼抓到最后楼
all_tiezi_urls = []
for i in range(0, 5):
# 构造url
tiezi_url = url + "&pn=" + str(i * 50)
# 获取每一页的帖子url
tiezis = get_tiezi_list(tiezi_url, session)
# 将所有帖子url加入到all_tiezi_urls中
all_tiezi_urls.extend(tiezis)
return all_tiezi_urls
# 获取当前页所有帖子列表的方法
def get_tiezi_list(tiezi_url, session):
# 获取某个帖子列表页面的网页内容
res = session.get(tiezi_url)
# 从中解析出每个帖子的链接
soup = BeautifulSoup(res.text, 'html.parser')
a_list= soup.find_all('a', class_='j_th_tit') #???
# 拼接出真实的帖子链接
static_tiezi_urls = []
for each in a_list:
static_tiezi_urls.append("http://tieba.baidu.com" + each.attrs['href'])
return static_tiezi_urls
if __name__ == '__main__':
session = login()
keyword = input('请输入贴吧名称:')
# 构建贴吧主页url
index_url = 'https://tieba.baidu.com/f?kw={0}&tab=good'.format(keyword)
# 获取帖子总页数(经过测试发现 不登录并不影响)
total_page = get_total_page(index_url, session)
# 获取每一页的帖子url 放在列表中
all_tiezi_urls = get_tiezi_url_list(total_page, index_url, session)
#以“关键字/数字序号.jpg”的形式保存爬取的图片
#判断文件夹是否存在 如果不存在 则先创建文件夹
img_dir = keyword
if (not os.path.exists(img_dir)):
os.mkdir(img_dir)
i = 0
for each in all_tiezi_urls:
# 获取帖子的具体内容
page = 1
while(True):
print('进入一个贴,第' + str(page) + '页')
res = session.get(each)
# 从中解析出图片url
soup = BeautifulSoup(res.text, 'html.parser')
img_urls = soup.find_all('img', class_='BDE_Image')
for img in img_urls:
i += 1
thumbnail = img.attrs['src']
pic_id = ''.join(re.findall(r'(?<=/)(?![\w\W]*?/).*(?=.jpg)', thumbnail))
tid = ''.join(list(re.findall(r'p/(.*)\?pn|p/(.*)$', each)[0]))
print("正在下载第" + str(i) + "张图片" )
high_img = 'http://tieba.baidu.com/photo/p?kw=' + keyword + '&flux=1&tid=' + tid + '&pic_id=' + pic_id
res_img = session.get(high_img)
soup_img = BeautifulSoup(res_img.text, 'html.parser')
# baidu老狗又调皮了
high_img_urls = ''.join(re.findall(r'(?<="waterurl":")(?![\w\W]*?"waterurl":").*(?="},"medium")', str(soup_img)))
with open(img_dir + "/" + str(i) + '.jpg', 'wb') as f:
f.write(session.get(high_img_urls).content)
if '>下一页</a>' in res.text:
page += 1
each = re.sub(r'\?pn(.*)?$', '', each)
each = each + '?pn=' + str(page)
else:
break
print("图片下载完毕!")
附录2
伸手党同学可能会说,算了吧老潘,你看你刚才也手滑去抓校花了什么糟糕台词?,干脆你直接放一些好看的校花图给我们看看吧。既然今天已经拖堂这么久了,潘老师就奖励大家,特选出无名校花一二三,各位一起放松一下。




现在开始评选第一届“Python杯”我心目中最美的校花奖项。请在评论区投出你庄严而珍贵的一票。