【5分钟实例】去除大量图片中重复的图片

需求假设
你的老板给你上万张候选人的证件照,但是由于某些原因,一部分人的照片有不止一张(重复了),让你把重复出现的照片删掉,下班之前整理好发给他。你一看表距离下班只剩5分钟了,加班是不可能加班的。

这时候你灵光一现,想起了python有图像处理模块
只需5分钟的操作
拿起键盘打开你最爱的IDE二话不说首先import以下必定要用到的库
import cv2
import numpy as np
import os
别急,这种任务网上肯定是有现成轮子的,直接借鉴就好。对于图像去重,主要思路有,md5比较法和感知哈希法。其中md5比较法的鲁棒性稍微低了点,有时候图片因为多次压制或其他因素导致md5变化,从而图片看起来一样,但是会被判做不同图片。
感知哈希算法是比较常用的方法,在硬币分类检测时老潘也尝试过,但是并不适用于那个场景。但是今天的场景是绝对适合的。其中感知哈希算法又可以细分出平均哈希(aHash),感知哈希(pHash),差异值哈希(dHash)三种。硬币分类里使用了pHash,对于这三种的对比,在一篇CSDN博文感知哈希 ,平均哈希,差异值哈希里面有详细的讲解和对比实验。
这里老潘在网上找到的一个现成的图片去重的脚本使用的是aHash
img = cv2.resize(img,(8,8))
avg_np = np.mean(img)
img = np.where(img>avg_np,1,0)
hash_dic[img_name] = img
读取每个图片,计算出他的aHash值,如果记录表里没有这个值,就把他和他的值存进去,如果有,证明重复,删掉这个图即可。思路很简单。
当然,这里并不是直接检测有没有一模一样的aHash值,而是检测有没有汉明距离小于某个值的,以防两个一样的图片因为微小的差异被漏检。
顺手再添加一个功能,有些人的照片可能损坏了或者夹杂了奇奇怪怪的不是图片的文件。我们把这种也剔除掉。
try:
img= cv2.imread(os.path.join(path, img_name))
img= cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
except:
os.remove(os.path.join(path, img_name))
print('wrong file')
continue
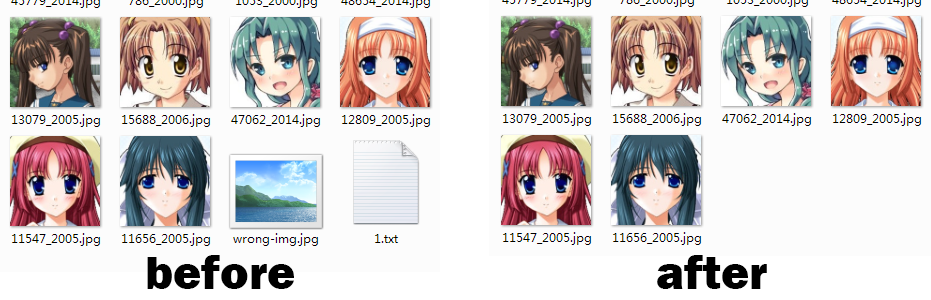
复制粘贴代码1秒钟,4分59秒钟用来运行代码。将筛选好的图片给正在加班的程序员,下班回家。
附录1
aHash到底可靠不可靠?会不会有误检和漏检?以这个现成脚本代码为例,做几个尝试性的实验看看。
实验1:普通去重,实验前后的图片集合如图所示。
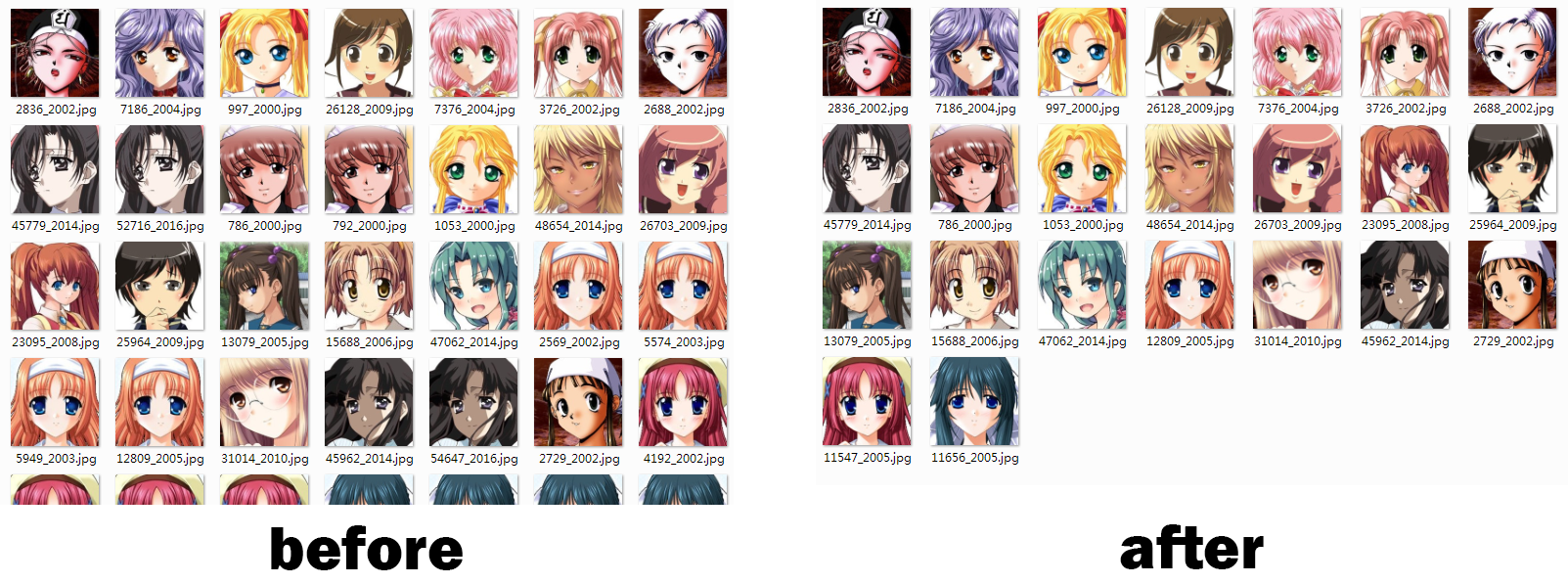
实验2:相似图片(我真的觉得这几位差不多,如有冒犯,狗妹纳赛)

实验3:相同图片不同饱和度(反正图片读进来都是要先转成灰度的,所以改变饱和度确实不会对改变aHash值有什么作用)

附录2
完整的开箱即用代码,也可以到github里面下载
'''
https://www.jianshu.com/p/5a7daa2123a8
'''
import cv2
import numpy as np
import os
if __name__ == '__main__':
path = './anim'
img_list = os.listdir(path)
hash_list = []
for ind, img_name in enumerate(img_list):
print('checking:', ind+1, 'from total:', len(img_list))
try:
img = cv2.imread(os.path.join(path, img_name))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
except:
os.remove(os.path.join(path, img_name))
print('wrong file')
continue
img = cv2.resize(img,(8,8))
avg_np = np.mean(img)
img = np.where(img>avg_np,1,0)
if len(hash_list)<1:
hash_list.append(img)
else:
for i in hash_list:
flag = True
dis = np.bitwise_xor(i,img)
if np.sum(dis) < 5:
flag = False
os.remove(os.path.join(path, img_name))
print('remove')
break
if flag:
hash_list.append(img)