复习Pytorch的使用方法,在套路的基础上灵活应变

本节的大部分代码参考了:莫烦python
这次只是一个学习记录,并不指望最后做个什么玩意儿出来。因为一直都是拿模板来改,这次想空手从网络结构到写成代码再到训练的过程完整走一遍。先试一个简单的案例,再尝试一步步深化。
首先试着写一个很简单的AutoEncoder的结构出来。根据快速理解,这个网络的结构应该是类似这样的
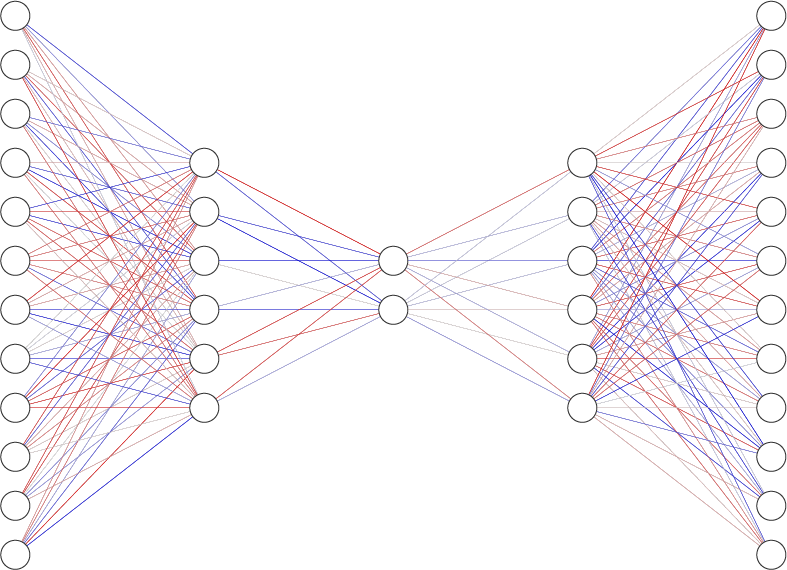
我稀薄的记忆告诉我,有两种方法构建网络,一种是直接写在Sequential里,一种是先定义层再定义连接。那这次两个方法都试试,用Sequential写一下前半部分的Encoder,用另一种方法写Decoder。而且以前甚至都没仔细看过具体class,init那块都长啥样,只管复制粘贴。这次仔细看看写写。
首先得写 class Net(nn.Module):,这里就有坑了,Module的M是大写。在这之后写一个def__init__(self):和一个def forward(self, x):,__init__里面定义层的信息,forward里面写网络的连接情况。另外,在def __init__(self):里面第一句要写super(Net,self).__init__()。剩下的部分就都是熟悉的味道了。
所以整个网络这个class就写成了这样
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# encoder
self.encoder = nn.Sequential(
nn.Flatten(start_dim=1),
nn.Linear(28 * 28, 128),
nn.LeakyReLU(inplace=True),
nn.Linear(128, 64),
nn.LeakyReLU(inplace=True),
nn.Linear(64, 32),
nn.LeakyReLU(inplace=True),
nn.Linear(32, 16),
nn.LeakyReLU(inplace=True),
nn.Linear(16, 8),
nn.LeakyReLU(inplace=True),
nn.Linear(8, 4),
)
# decoder
self.LeakyReLU = nn.LeakyReLU(inplace=True)
self.Linear_0 = nn.Linear(4, 8)
self.Linear_1 = nn.Linear(8, 16)
self.Linear_2 = nn.Linear(16, 32)
self.Linear_3 = nn.Linear(32, 64)
self.Linear_4 = nn.Linear(64, 128)
self.Linear_5 = nn.Linear(128, 28 * 28)
self.Sigmoid = nn.Sigmoid()
def forward(self, x):
# x = x.view(-1, 28*28)
x_encoded = self.encoder(x)
x_decoded = self.Linear_0(x_encoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Linear_1(x_decoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Linear_2(x_decoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Linear_3(x_decoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Linear_4(x_decoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Linear_5(x_decoded)
x_decoded = self.LeakyReLU(x_decoded)
x_decoded = self.Sigmoid(x_decoded)
x_decoded = x_decoded.view(-1, 28, 28)
return x_encoded, x_decoded
写的时候也遇到了一些问题,首先是一开始指定了输入数据先进入nn.Flatten(),这步是打算把图片展成一维,结果发现输入尺寸不匹配,经过检查之后发现nn.Flatten()如果不指定任何参数,会直接把输入的整个[batch_size, channel, weight, height]尺寸的tensor直接展平成一维数组[1, batch_size * channel * weight * height],但是我们期望的展平是展成[batch_size, channel * weight * height]的。故这里的nn.Flatten()需要指定一个参数nn.Flatten(start_dim=1),也可以用另一种方案,对于输入x,使x = x.view(-1, channel * weight * height)。
关于输入tensor的尺寸形状问题,可见:Pytorch的参数“batch_first”的理解
这里示范一下flatten的两个参数的情况,torch.flatten()和nn.Flatten()的参数效果是一样的
start_dim=1表示展平的开始维度,例如这个tensor的第一个28这一维以及往后的维度都压在一起:
view_data = train_data.train_data[idx]
print(view_data.shape)
view_data = torch.flatten(view_data,start_dim=1)
print(view_data.shape)
>>>torch.Size([6, 28, 28])
>>>torch.Size([6, 784])
start_dim=0自然就是从最开始的一个维度压缩,看来不指定参数的话默认就是这个情景:
view_data = train_data.train_data[idx]
print(view_data.shape)
view_data = torch.flatten(view_data,start_dim=0)
print(view_data.shape)
>>>torch.Size([6, 28, 28])
>>>torch.Size([4704])
end_dim=1表示展平的停止维度,例如这个tensor的第一个28这一维以及之前的维度都压在一起:
view_data = train_data.train_data[idx]
print(view_data.shape)
view_data = torch.flatten(view_data,end_dim=1)
print(view_data.shape)
>>>torch.Size([6, 28, 28])
>>>torch.Size([168, 28])
第二是无意间看到的关于优化性能的一些建议。对于relu尽量设置inplace=True可以节省一些显存,那我们就把__init__里面的relu层都加一下这个参数吧。
对于输出,重新resize成图片的尺寸即可,因为用的是灰度图片,所以resize可以省略通道那个维度,直接做成[batch_size, width, height]
接着加载数据使用以下方法,需要数据增广的话就把以前做过的复制粘贴过来即可,这里没什么要注意的。
train_data = torchvision.datasets.MNIST(root='./dataset/', train=True,
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST,
)
trainloader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE,shuffle=True)
指定设备,直接用倒背如流的
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
之后给网络和tensor都to(device)即可。
Net = Net().to(device)
接着是optimizer和loss function
optimizer = torch.optim.Adam(Net.parameters(), lr=LR)
loss_func = nn.MSELoss()
接着写一个for循环,一个循环是一个epoch,这里面,先for step, (data, label) in enumerate(trainloader):,在往里套数据的加载,计算,误差,老三套,大体结构是固定的。补充一点关于model.train(),model.eval()和with torch.no_grad():的关系,train和eval指定模型状态,如果模型存在BN和dropout,测试时不指定状态为eval()的话最后计算结果会不对劲。with torch.no_grad():是不计算存储梯度状态,是为了节约显存。详细信息参考:pytorch中model eval和torchno grad()的区别
for epoch in range(EPOCH):
for step, (data, label) in enumerate(trainloader):
Net.train()
data = data.squeeze().to(device)
encoded, decoded = Net(data)
loss = loss_func(decoded, data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
每个epoch里面放一个步数检测,一定步数以后输出一个记录出来,这里建议把验证、测试等等不需要计算梯度的过程套一个with torch.no_grad():,这样不需要在输出loss和网络生成的结果时指定detach()了,否则要指定。同时注意网络输出如果运行在GPU上的,要取回CPU才能输出观察。
if step % 100 == 0:
Net.eval()
with torch.no_grad():
print('Epoch: %d | train loss:%.4f' % (epoch, loss.item()))
_, decoded = Net(view_data)
if decoded.device != 'cpu':
decoded = decoded.to('cpu')
# 这里对view_data可视化
这里出现了预览用的数据view_data我前面还没讲,我不想让可视化的步骤打乱整体思路,可视化具体操作太灵活了,具体的就看代码吧。只写一下view_data的选择过程:选择train_data的targets等于0~9的对应位置,在train_data的data里取出这些位置的东西,就是对应0-9的数字的图片了。我总觉得这个可以再写简练一点,但是水平有限,不会再简化了。
idx = []
for i in range(N_TEST):
idx.append((train_data.targets == i).nonzero()[0].item())
view_data = train_data.data[idx]
继续堆功能,实际训练可能会出现突然死机或者断电或者训练时想要暂停一下,这就需要保存一下网络的状态,回头再加载进来继续用,但是同时还应该保存optimizer的状态,如果有学习率计划的话还得存一下epoch,有的网络可能还得存一下loss,等等,这些信息可以直接用torch.save()存下来。具体保存的方法如下:
#每个epoch结束后保存一个checkpoint
torch.save({'epoch': epoch,
'model_state_dict':Net.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
}, 'checkpoint/ckpt.pth')
执行这个之前首先要保证checkpoint这个路径是存在的,这里就去前面加一个创建路径的代码即可,可以和检测加载checkpoint的代码放在一起。这段代码需要在进行训练的循环之前,在初始化模型与优化器之后。具体加载的代码如下,主要的操作就是将存着的数据赋给一些变量里。
# 读一个checkpoint,如果存在的话
start_epoch = 0
if os.path.exists('checkpoint'):
if os.path.exists('checkpoint/ckpt.pth'):
print('Checkpoint exists, reading weights from checkpoint...')
checkpoint = torch.load('checkpoint/ckpt.pth')
Net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch'] + 1
else:
os.makedirs('checkpoint')
这里读了起始的epoch,在训练时那个for循环就要从这个start_epoch开始计数了,
for epoch in range(start_epoch, EPOCH):
# ……
可以看一下效果,我在epoch执行完第2次的时候点停止,这时存下的状态就是第2轮结束时的整个状态,然后再运行,可以看到目前运行的是第3个epoch,是接着第2轮的后面继续的。

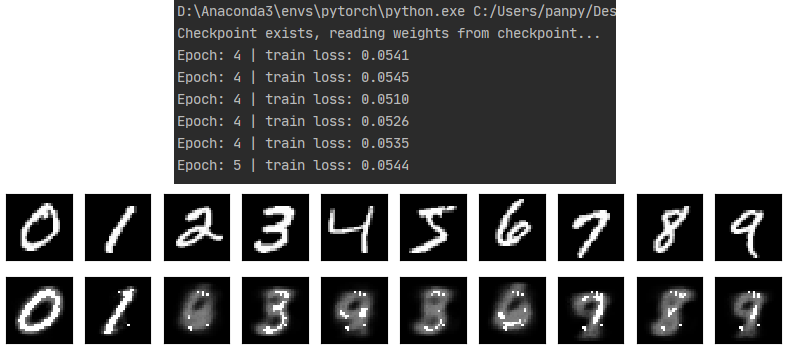
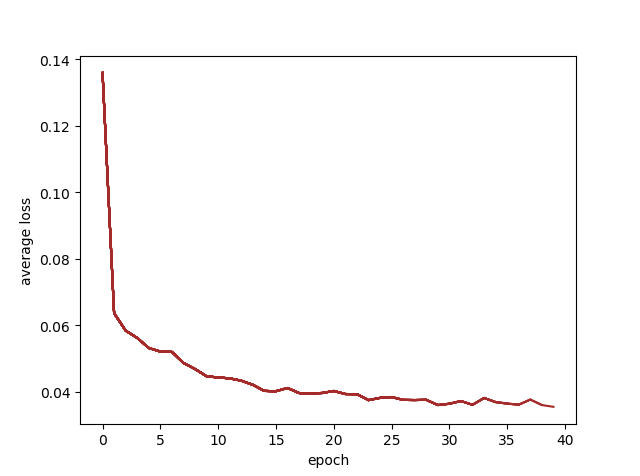
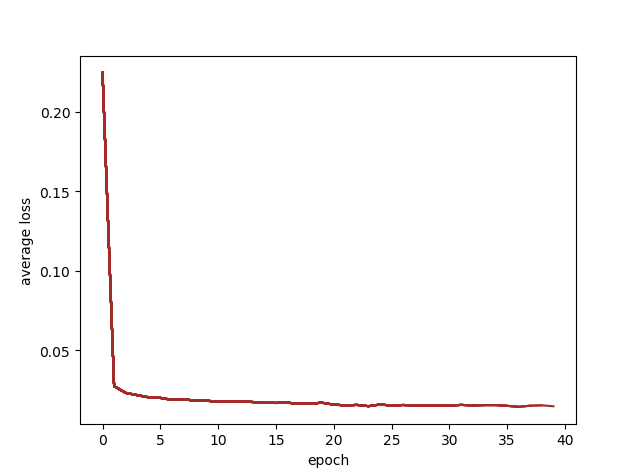
再之后我突然想加一个统计loss并且画出图的功能,可视化的地方略过,主要说一下统计loss的思考。首先我想统计每一次的loss输出,但是因为在每个step拿出loss的值,往后还得涉及到存取,一系列操作会很麻烦,这里先考虑以每个epoch作为统计时间单位。我选择用每个epoch内每100步的loss的均值作为输出值。没有选择从头开始的所有均值是考虑到,如果后面loss不再降低,但是均值还会随着步数增大而降低。使用每个epoch的均值就不会出现这个问题,可以看出在第几epoch收敛了。同时checkpoint文件也得加入loss情况的记录。
首先在epoch循环的外面放一个avg_losses= []作为每轮的平均值的记录,在每轮epoch循环一开始就给一个avg_loss = 0和flag = 0,在进行每100步的输出日志时顺便记一下avg_loss += loss.item(),在epoch循环马上要结束的地方,在保存checkpoint文件之前,计算一下这一epoch的loss均值,想画图就画出来,懒得画就直接存进checkpoint
avg_loss = avg_loss / flag
print('Epoch %d average loss: %.4f' % (epoch, avg_loss))
avg_losses.append(avg_loss)
x1 = range(0, len(avg_losses))
y1 = avg_losses
plt.figure(2)
plt.plot(x1, y1, color='yellow', linestyle='-')
for text_x, text_y in zip(x1, y1): # epoch多了之后会挤成一团,实际用的时候可以不显示
plt.text(text_x, text_y, '%.4f' % text_y, ha='center', va='bottom',fontsize=7)
plt.xlabel('epoch') plt.ylabel('average loss')
plt.draw()
plt.pause(0.05)

我看到这才发现,忘记做训练完毕保存网络的步骤了,给他存一下,如果以后要做预测的话可以直接加载。
if not (os.path.exists('model')):
os.makedirs('model')
torch.save(Net.state_dict(), 'model/net.pth')
print('model saved!')
既然都做到这了,不加一个lr_scheduler总感觉不完整。观察了上面那个loss曲线,我决定在20epoch之后减小学习率,至于选30epoch或者加大epoch效果怎么样我不想尝试了,这块我就随意做一下先。
scheduler =torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[20], gamma=0.2)
最初我写的scheduler.step(epoch),这样保存checkpoint并且再加载的时候能衔接上。但是这里面指定参数的话会报警告说这个参数不是必需的,可能在以后的版本会取消这种用法?不懂,但是我看源码的时候发现scheduler也有state_dict和load_state_dict,所以我就把这个状态的读写也用checkpoint文件记录一下,在开始训练之前先读一下scheduler的状态
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
这应该是比较正统的做法。
(在这个任务上加不加lr_scheduler影响都不大)
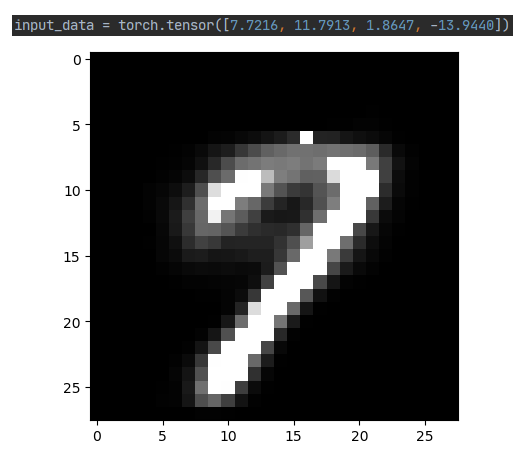
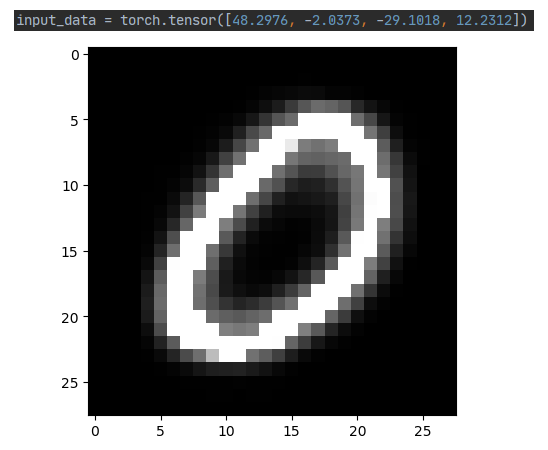
再尝试一下只构建后半段解码器,用保存的权重初始化,并且从编码器对一种数字图案的低维编码恢复出数字图片。先构建后半段的网络,本来想写个Encoder在写个Decoder然后再Net里面拼起来,但是好像有点问题。关于如何从保存的权重里只读取一部分,其实是个千层饼行为,先拿出这个网络的权重信息,再去对比加载的权重信息,再用重复的部分替换网络的权重,再让网络读取这个权重信息。具体操作可见:Pytorch迁移学习加载部分预训练权重
decoder = Decoder().eval()
model_dict = decoder.state_dict()
pretrained_dict =torch.load('model/net.pth')
pretrained_dict = {k: v for k, v inpretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
decoder.load_state_dict(model_dict)
with torch.no_grad():
output = decoder(input_data)
plt.imshow(output[0], cmap='gray')
plt.show()
再用一用卷积网络试试,之前的网络都是用全连接层进行推理计算的,这里把里面的层改成卷积和反卷积试一试效果。使用卷积网络的话,需要考虑一下图片输入之后的尺寸变化情况。这里先毫不讲道理地随意设计一下卷积结构的自编码器。

class DoubleConvNet(nn.Module):
def __init__(self):
super(DoubleConvNet, self).__init__()
self.encoder_1 = nn.Sequential(
nn.Conv2d(1, 5, 8, 4, 2), # 7x7x5
nn.BatchNorm2d(5),
nn.LeakyReLU(True),
nn.Conv2d(5, 7, 5, 1, 0), # 3x3x7
nn.BatchNorm2d(7),
nn.LeakyReLU(True),
nn.Conv2d(7, 9, 2, 1, 0), #2x2x19
nn.BatchNorm2d(9),
nn.LeakyReLU(True),
nn.Conv2d(9, 10, 2, 1, 0), #1x1x11
nn.Sigmoid(),
)
self.encoder_2 = nn.Sequential(
nn.Conv2d(1, 5, 14, 1, 0), #15x15x5
nn.BatchNorm2d(5),
nn.LeakyReLU(True),
nn.Conv2d(5, 7, 8, 1, 0), # 8x8x7
nn.BatchNorm2d(7),
nn.LeakyReLU(True),
nn.Conv2d(7, 9, 4, 4, 0), # 2x2x9
nn.BatchNorm2d(9),
nn.LeakyReLU(True),
nn.Conv2d(9, 10, 2, 1, 0), #1x1x11
nn.Sigmoid(),
)
self.decoder_1 = nn.Sequential(
nn.ConvTranspose2d(20, 9, 2, 1, 0),
nn.BatchNorm2d(9),
nn.ReLU(True),
nn.ConvTranspose2d(9, 7, 2, 1, 0),
nn.BatchNorm2d(7),
nn.ReLU(True),
nn.ConvTranspose2d(7, 5, 5, 1, 0),
nn.BatchNorm2d(5),
nn.ReLU(True),
nn.ConvTranspose2d(5, 1, 8, 4, 2),
nn.Sigmoid()
)
self.decoder_2 = nn.Sequential(
nn.ConvTranspose2d(20, 9, 2, 1, 0),
nn.BatchNorm2d(9),
nn.ReLU(True),
nn.ConvTranspose2d(9, 7, 4, 4, 0),
nn.BatchNorm2d(7),
nn.ReLU(True),
nn.ConvTranspose2d(7, 5, 8, 1, 0),
nn.BatchNorm2d(5),
nn.ReLU(True),
nn.ConvTranspose2d(5, 1, 14, 1, 0),
nn.Sigmoid()
)
def forward(self, x):
encoded_1 = self.encoder_1(x)
encoded_2 = self.encoder_2(x)
encoded = torch.cat((encoded_1, encoded_2), 1)
decoded_1 = self.decoder_1(encoded)
decoded_2 = self.decoder_2(encoded)
decoded = decoded_1 + decoded_2
return encoded, decoded
对于卷积网络,可以设置一个参数torch.backends.cudnn.benchmark= True,这个参数可以在网络结构、输入尺寸不变的情况下预优化网络。详细信息参考:torch.backends.cudnn.benchmark ?!
对于ConvTranspose2d和Conv2d的关系,根据实验和查找资料,这两个的操作是完全互逆的,参数设置都一样。详细信息参考:pytorch演示卷积和反卷积运算
对比保存的全连接网络(879kb)和卷积网络(70kb),发现卷积网络占用空间更少。
卷积网络的loss更低,生成的结果也更好。
卷积网络:

全连接网络:

另附本次练习所用全部代码:GitHub
(最后再说一句,如果你运行报错的话,先看看是不是上一次的chechpoint记录文件没删,如果修改了代码或者重新运行代码,还是会读上次的ckpt文件,我没完善这里,学有余力的同学补充一下吧。)