pytorch的一些杂技(记)

1. pytorch加载预训练权重
1.1 加载一部分权重
实际上有两种思路加载预训练权重。
先说第一种:预训练权重不带最后一层fc,或者要加载的权重和自己的网络之间要取一个交集,这种就用以下方法
# ref: https://blog.csdn.net/xzy5210123/article/details/88598436
pretrained_dict = torch.load('pretrainedXXXX.pth')
model = MyNetXXXX()
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
1.2 只改最后一层
另一种是,自己用一个数据集做了预训练,例如UCF101,有101类,最后fc层的out也是101维的。而实际任务只是类别数变得不一样,其他结构均不变,这时候可以用一个简单的方法。
# ref: https://blog.csdn.net/KHFlash/article/details/82345441
net = SameWithPretrainingNetXXXX()
net.load_state_dict(torch.load('pretrainedXXXX.pth')
fc_features = model.fc.in_features
net.fc = nn.Linear(fc_features, 9)
net = net.to(DEVICE)
如果是在GPU上做,这里一定要留意在最后加net = net.to(DEVICE),否则会报玄学错误:RuntimeError: CUDA error: an illegal memory access was encountered
1.3 模型涉及到nn.DataParallel的话
还有一个坑是,如果在多GPU上训练时,保存模型权重要使用torch.save(model.module.state_dict(), model_out_path)的方法,否则会报一种错误:
RuntimeError: Error(s) in loading state_dict for ResNet:
Missing key(s) in state_dict: "conv_1.weight", "bn1.weight", "bn1.bias", ......
Unexpected key(s) in state_dict: "module.conv_1.weight", "module.bn1.weight", "module.bn1.bias", ......
如果想要抢救一下的话,可以看到错误信息提示key中多了‘.module’,那么,只要把‘.module’移除即可:
# original saved file with DataParallel
state_dict = torch.load(model_path)
# create new OrderedDict that does not contain `module.`
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k.replace('.module.','.') # remove `module.`
new_state_dict[name] = v
# load params
net.load_state_dict(new_state_dict)
ref: https://blog.csdn.net/weixin_41735859/article/details/108610687
1.4 从API下载在线的预训练模型
有时候我们不想让torchvision.models下载的权重模型存到默认的缓存位置,想让他存在某个集中管理的地方或者本项目路径下,可以在命令行设置一下环境变量:
(win)
SET TORCH_HOME=.cache
(linux)
export TORCH_HOME=.cache
如果是使用了huggingface加载transformer,他的缓存路径环境变量是
(win)
SET TRANSFORMERS_CACHE=.cache/huggingface/hub
(linux)
export TRANSFORMERS_CACHE=.cache/huggingface/hub
pytorch冻结部分层的权重
ref:
https://www.jianshu.com/p/fcafcfb3d887
想要只训练网络最后的全连接层,可先查看所有的net.named_parameters()找到对应的参数名称,然后使用锁定梯度的方法冻结权重训练。
for k,v in model.named_parameters():
if k not in ['fc.weight', 'fc.bias']:
v.requires_grad=False
不同参数设置不同学习率
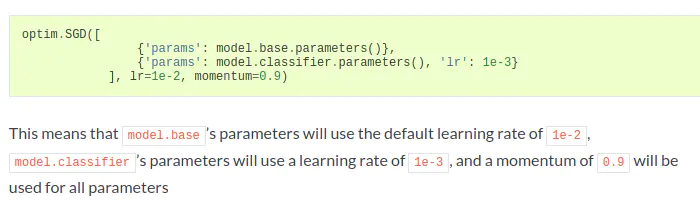
一个网络的输出是另一个的输入,只训练后半个网络

pytorch的dataset和dataloader长度
len(dataset)返回的是在dataset类里面的def __len__(self):返回的长度。
len(dataloader)返回的是在dataset长度除以batch_size,即实际一个epoch内执行的步数。
再谈torchvision.transforms
早在上个月我就已经思考明白了关于视频图像序列的图像增广的细节。即每次调用一下img=transforms(img),就会触发一次各种随机翻转旋转等的随机数设置。如果针对序列里的图片,在每次读进来的时候或者用for循环,对每个图片做transforms,会导致一系列图片明暗色彩角度各不相同。对于序列图片,如果涉及到这种增广操作,我只能想到一种办法,即重写所用的transforms操作,每次调用的时候传进整个图片序列,这样就只调用了一次,也就只初始化了一个随机数,这样再去做ColorJitter()或者RandomHorizontalFlip()等随机操作里面对张量切片,对每个切片做变换,这样一系列图片可以有相同随机数下的变换操作。如果只是要做Resize()或者ToTensor()之类的那就无所谓了,调用多少次都是一样的结果。
之所以今天又写这个,是因为我耗了一下午,自以为把加载数据的部分优化了,结果发现又走到了错误的道路上。。。
还有,compose里面要用方括号括住各个操作,大括号会导致顺序和写的顺序不一致,导致玄学问题
pytorch指定不同层数以不同的LR
ref:
pytorch在不同的层使用不同的学习率
https://blog.csdn.net/wangbin12122224/article/details/79949824
有时候我们希望某些层的学习率与整个网络有些差别,这里我简单介绍一下在pytorch里如何设置,方法略麻烦,如果有更好的方法,请务必教我:
首先我们定义一个网络:
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 1)
self.conv2 = nn.Conv2d(64, 64, 1)
self.conv3 = nn.Conv2d(64, 64, 1)
self.conv4 = nn.Conv2d(64, 64, 1)
self.conv5 = nn.Conv2d(64, 64, 1)
def forward(self, x):
out = conv5(conv4(conv3(conv2(conv1(x)))))
return out
我们希望conv5学习率是其他层的100倍,我们可以:
net = net()
lr = 0.001
conv5_params = list(map(id, net.conv5.parameters()))
base_params = filter(lambda p: id(p) not in conv5_params,
net.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': net.conv5.parameters(), 'lr': lr * 100},
, lr=lr, momentum=0.9)
如果多层,则:
conv5_params = list(map(id, net.conv5.parameters()))
conv4_params = list(map(id, net.conv4.parameters()))
base_params = filter(lambda p: id(p) not in conv5_params + conv4_params,
net.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': net.conv5.parameters(), 'lr': lr * 100},
{'params': net.conv4.parameters(), 'lr': lr * 100},
, lr=lr, momentum=0.9)
pytorch卷积层的groups参数
下面是官方文档对于groups的解释。简单来说就是输入和输出都会被划成groups个组,groups个卷积层并列操作。输入和输出的维度还是总的维度数。
groups controls the connections between inputs and outputs. in_channels and out_channels must both be divisible by groups. For example,
At groups=1, all inputs are convolved to all outputs.
At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels, and producing half the output channels, and both subsequently concatenated.
At groups=in_channels, each input channel is convolved with its own set of filters, of size ⌊out_channels/in_channels⌋ .
pytorch hook
ref:
https://zhuanlan.zhihu.com/p/75054200
https://blog.csdn.net/winycg/article/details/100695373
https://oldpan.me/archives/pytorch-autograd-hook
多GPU并行
首先使用os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1, 2, 3"指定准备使用的GPU
之后使用
Net = net(args)
Net = torch.nn.DataParallel(Net)
Net = Net.to(device)
之后按照正常方法使用即可,需要存权重的话,要用下面这个方法保存
torch.save(model.module.state_dict(), model_out_path)
Net.parameters获取网络参数
Net.parameters返回一个generator,根据官方的用法,通过for循环得出网络各层的参数,
Example::
>>> for param in model.parameters():
>>> print(type(param), param.size())
<class 'torch.Tensor'> (20L,)
<class 'torch.Tensor'> (20L, 1L, 5L, 5L)
但param的类型仍然是一个封装过的parameter类型,需要通过param.data来取出里面的tensor数据
PS. 补充两个链接,这个作为Todo
- 直接在网络中定义feature,直接导出:https://www.jianshu.com/p/0a23db1df55a
比如,在这个例子中我想获得fc前面的特征,那么我就在前面加一句self.feature=x,然后再需要的地方调用model.feature即可得到。
- 获取Pytorch中间某一层权重或者特征:https://blog.csdn.net/happyday_d/article/details/88974361
嵌套列表以及列表包含Tensor的展开
python的list里面如果嵌套的是tensor,需要先将tensor转成list,然后再通过嵌套列表展开的方法。由于tensor维数一般比较多,所以解list以后,这个list的嵌套层数会比较深,需要用递归的方法解套,才能把这个list转成一维list,最终化为tensor
例:把一个(2, 3, 4)形状的tensor转成list:
x = torch.zeros(2, 3, 4)
x_list = x.numpy().tolist()
这个x_list长2,每个list元素长3,最内层的list有4个数字。
通过以下方法解开嵌套层数很大的list:
def flat(nums):
res = []
for i in nums:
if isinstance(i, list):
res.extend(flat(i))
else:
res.append(i)
return res
最终使用torch.Tensor(x_list)把一个list化成tensor