Scrapy爬虫时的一些细节

一些bug
配置scrapy的时候,如果发现爬取图片时,日志里返回链接正常但就是没有图片保存下来的话,使用
pip install pillow
安装一下PIL模块再尝试。
之前在本地的conda环境下,如果缺失PIL模块会直接报错出来,但是在服务器上,我直接部署到了系统python环境里,不知为何缺少了PIL却没有报错。
正确使用代理ip的方法
在设置的时候用http://xx.xx.xx.xx:xxxx的方法设置,即设置为http模式,如果用了https设置的代理,会出现
<twisted.python.failure.Failure OpenSSL.SSL.Error: [('SSL routines', 'ssl3_get_record', 'wrong version number')]>这种报错信息。
无所谓要爬的网站是http还是https,代理ip都要设置为http才可以。
日志太大
程序挂到后台运行,保存的日志会越来越大,一个偷懒的办法是到日志的目录下,执行
cat /dev/null > nohup.out
可以不打断进程的情况下,清空日志
断点续传(爬)
只需要启动时加入参数即可
scrapy crawl PAPAPA -s JOBDIR=ckpt/PAPAPA
这样,就是在ckpt这个文件夹下面,给PAPAPA这个爬虫保存了实时爬取进度。下次还执行这个命令,就会自动读取这个进度。
如果结合了nohup把爬虫挂起的话,想要完整中断爬虫,就使用kill 8888对进程发送SIGTERM,之后等待进程自动结束即可。避免强退,否则会造成断点处混乱。
在chrome的console里面使用xpath定位元素
$x('xpath表达式')
一个细节的地方是要注意有时候表达式里面有引号,要注意和最外层引号区分开,一般xpath里多见双引号,所以最好用单引号做外层的引号。
扩展:ccs表达式:$("css表达式")或者$$("css表达式")
ref: https://blog.csdn.net/jamieblue1/article/details/101075193
scrapy模拟登录
首先需要分析网站登录的时候发送了哪些信息,以postcrossing.com举例,在登录表单上检查信息,会看到这么些东西:
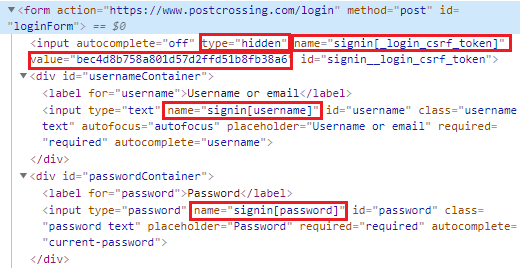
用户名和密码不用多说,另外还有一个hidden的东西,登录的时候这个也要传走,(但是我在实验的时候发现不带这个值直接用名字密码也能登)
对于在建立formdata的时候,用什么作为字典的键值?要查看页面提交信息,具体如何查看提交上去的信息,可以参考该链接:https://mofanpy.com/tutorials/data-manipulation/scraping/requests/
这个
<form>里面有一些<input>个 tag, 我们仔细看到<input>里面的这个值 name="firstname" 和 name="lastname", 这两个就是我们要 post 提交上去的关键信息了. 我们填好姓名, 为了记录点击 submit 后, 浏览器究竟发生了什么翻天覆地的变化, 我们在 inspect 窗口, 选择Network, 勾选Preserve log, 再点击submit, 你就能看到服务器返回给你定制化后的页面时, 你使用的方法和数据.
在本例中,上传的登录内容如图:
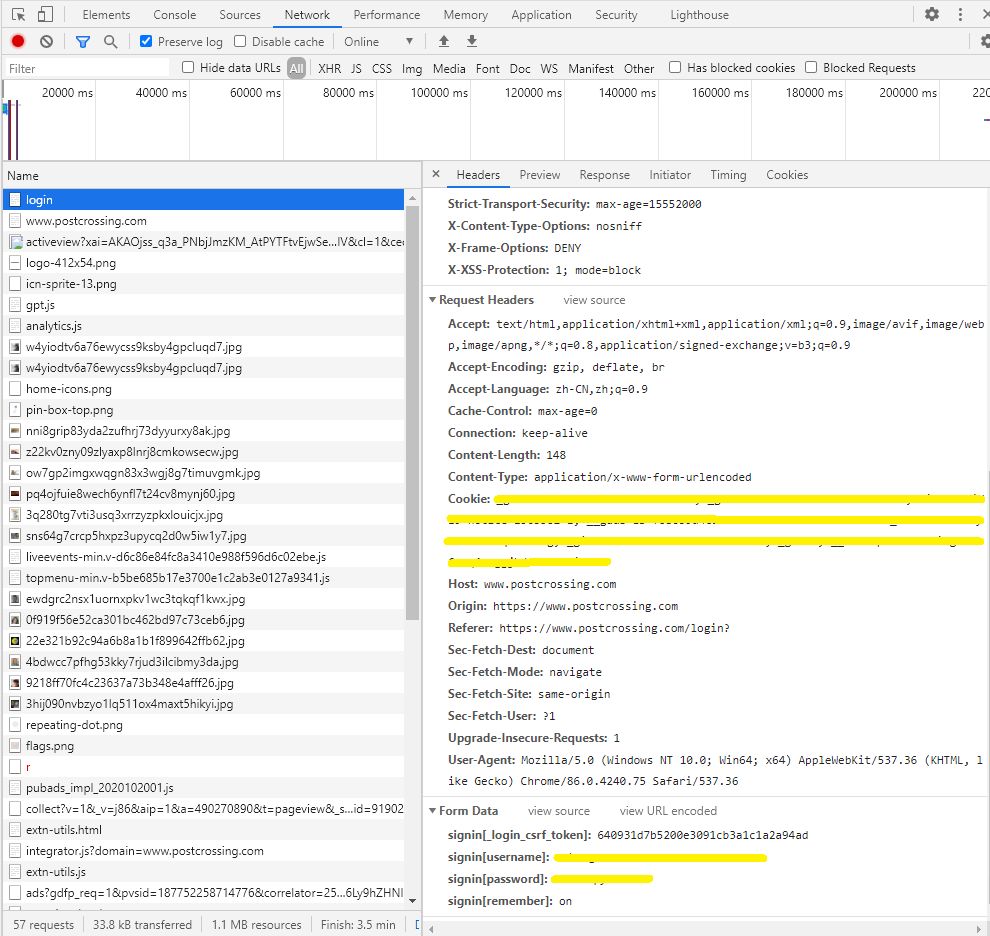
具体而言,怎么登录?在Spider脚本里的class XXSpider里面写下面这个函数
def start_requests(self):
yield Request('https://www.postcrossing.com/login', meta={"cookiejar": 1}, callback=self.post_login)
这样,程序一开始会Request这个login界面,紧接着在这个页面上进行callback即post_login所做的操作。
post_login的内容是:
def post_login(self, response):
token = response.xpath('//*[@id="signin__login_csrf_token"]/@value').extract_first()
# print('login_csrf_token: ', token)
form_data = {
'signin[_login_csrf_token]': token,
'signin[username]': 'XXXXXX',
'signin[password]': 'YYYYYY'
}
yield FormRequest.from_response(response, formdata=form_data,
meta={"cookiejar": response.meta['cookiejar']},
callback=self.country_gallery
)
其中,token获取了那个隐藏的会在登录时一同上传的神秘值,form_data构造了登录时需要的信息。通过FormRequest.from_response对response过来的内容(就是刚刚的登录页面)进行提交表单操作,用meta记下cookie信息。后续所有的Request都可以用这个cookie。
ref:
https://scrapy-cookbook.readthedocs.io/zh_CN/latest/scrapy-11.html
https://www.jianshu.com/p/404e4ac156a6
xpath解析内容为空
第一种情况是解析的页面不对,造成页面不对的原因是调用这个函数的上一级函数传过来的页面不对(其实就是上一级函数的Request里面那个url写的并不是自己要解析的那个)。一般就是字母拼错,页面层级搞混了,需要自己仔细检查。又或者是这个页面需要登录才能正常显示,不登陆的话进的是登录页面而不是内容页面,这就又回到了上一条需要做的事情。
第二种情况是user-agent的问题,在settings.py里加入
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
再尝试即可。
pandas获取某个值所在的行号
df[df['要检索的列'].isin([目标值]])]
这样可以返回一个新的df,里面只有符合要求的一个条目。这时候可以再从里面取其他的属性
例如,对下图这样的df查询'Code'为'CN'的条目
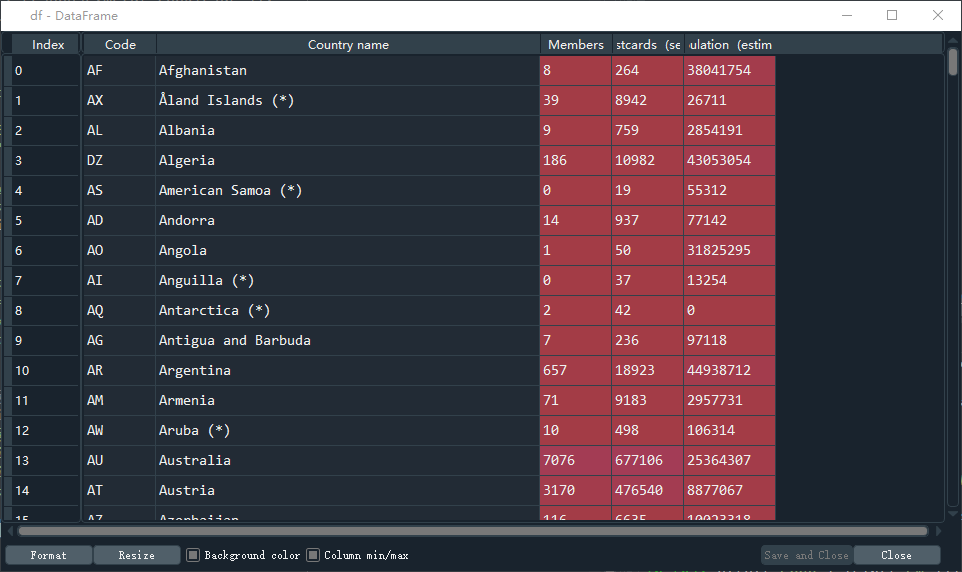
执行以下操作
new_df = df[df['Code'].isin(['CN'])]

要取出某一个值,可以
string = new_df['Country name'].tolist()[0]
print(string)
>>> China
注意安全
在做的时候,有可能涉及到需要登录的操作。这里尽量不要用自己常用的账号(这个应该是常识),但是同时还要注意也尽量避免用自己常用的IP。
因为有时候操作不当会导致IP被封,与此同时在这个IP上活跃的其他账号也容易被一并误伤。
【更正:测试的时候也绝对不要在自己本地机器上做,测试也上服务器做,本地一封就整个ip被ban,会连带账号一起遭殃。】
当然,能被服务器ban掉,那证明操作有点过火,所以一定要控制访问间隔,不要太密集的连续发送请求。不着急的话5s一次,再快就有风险了。
在合理的情况下使用自适应爬虫强度
在setting.py里面打开以下内容,可以实现由scrapy自动管理爬虫强度,避免上述手动设置访问间隔的麻烦
AUTOTHROTTLE_ENABLED = True
其他参数保持默认即可。这样的话,刚开始爬虫程序会先以默认的5s间隔爬,之后会逐步调整,加快或者减慢爬取速度。