【5分钟实例】按名字从大量简历中筛出需要的简历

水一篇。开个新坑,本系列重点打造能够在5分钟内完成的又简单又实用的实例。今天以办公场景比较常见的一个需求为例。具体场景如下。
需求假设
你的老板给你上万份候选人交的简历,又给了你一个Excel表格,让你把表格里的人的简历挑出来,下班之前发给他。你一看表距离下班只剩5分钟了,加班是不可能加班的。
这时候你定睛一看,所有的简历文件名里面都包含人名。
只需5分钟的操作
拿起键盘打开你最爱的IDE二话不说首先import以下必定要用到的库
import pandas as pd
import os
from shutil import copyfile
打开Excel表格看一眼,找到“姓名”所在的列

是第一列,所以直接读第一列进来即可
df = pd.read_excel(menu_path, usecols=[0])
之后去遍历存放简历的文件夹下的所有简历文件
for maindir, subdir, filename in os.walk(resume_path):
for i, file in enumerate(filename):
对每个遍历到的文件,先去除文件名里面的空格,以免两个字的人名中间有空格,干扰识别。但是又不能直接把变量file给改变,否则后面复制文件时会找不到文件。
file_no_space = ''.join(file.split())
这时候再遍历读进来的Excel的人名信息,逐条检查是否能和这个文件名匹配上人名。若可以匹配到,那就把这个文件复制走。
for key in df['姓名']:
if key in file_no_space:
copyfile(os.path.join(maindir, file), os.path.join(destination_path, file))
print(file)
拓展功能,如果想要把顺序也排好,那就只需记录一下目前匹配到的情况下,这个人名在Excel表格里的序号。可以对上面这一块代码做以下改动。首先使用enumerate()迭代df['姓名'],这样可以启用循环时的索引计数(我不知道这到底叫什么,我就这样称呼了),之后输出文件时将这个索引加在文件名最开头,就能实现按照Excel里面的人名顺序排序简历。
for i, key in enumerate(df['姓名']):
if key in file_no_space:
copyfile(os.path.join(maindir, file), os.path.join(destination_path, str(i)+file))
print(file)
结束。看一下效果,证明我不是在胡扯,是真的可以用。文件标号1缺失了,顺便还能发现有人没交简历。看一眼时间离下班还剩5分01秒。
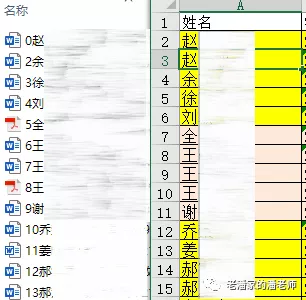
对于重名的问题,可以按照“学号”,或者“身份证号”等其他不易重复的值作为匹配的键值。但前提是要让简历名字里包含这些信息。
附录
全部代码如下。或者到github下载。
# -*- coding: utf-8 -*-
import pandas as pd
import os
from shutil import copyfile
resume_path = './resume'
menu_path = './1组分组名单.xlsx'
destination_path = './sorted'
if not os.path.exists(destination_path):
os.makedirs(destination_path)
df = pd.read_excel(menu_path, usecols=[0]) # 以第1列(人名)作为检索key
for maindir, subdir, filename in os.walk(resume_path):
for i, file in enumerate(filename):
file_no_space = ''.join(file.split())
for i, key in enumerate(df['姓名']):
if key in file_no_space:
copyfile(os.path.join(maindir, file), os.path.join(destination_path, str(i)+file))
print(file)