光流法应用——自适应检测视频火车速度

本文参考资料:
[1] OpenCV-Python Tutorials » Video Analysis » Optical Flow
[2] Good Features to Track
[3] Pyramidal Implementation of the Lucas Kanade Feature Tracker Description of the algorithm
代码地址:https://github.com/divertingPan/video_scanner/blob/main/main_v0.2.py
本篇是接续【硬核摄影】给火车拍个全身照的内容。使用自动脚本生成火车视频扫描图存在一个问题:如果火车的运动速度是变化的,只使用手动给定的固定扫描间隔是会有大问题的。例如下图。

显然,火车在减速,车头位置扫描间隔正合适,而车尾的扫描间隔太大了。如果能够根据当前车速自动判断应该用多宽的扫描间隔就能够解决这个问题。
那么就应该获得前后两帧之间物体运动的距离,最好连方向也能判断出来,这样直接就可以自动判断拼接方向了。
显然,这个需求完全可以用光流法来实现。具体的算法原理和例程在开头的参考资料内,留作课后阅读材料。利用opencv可以直接获取视频中关键点在前后两帧的定位,利用这个定位的横向差值可以获得这一刻的物体运动速度,差值的正负则代表运动方向。这样利用自动检测的运动信息就可以实现变速物体的扫描了,并且还可以省下自己去数格子算运动距离的精力。
先获取两个相邻帧,转成灰度图像
vc = cv2.VideoCapture(video_path)
rval = vc.isOpened()
vc.set(cv2.CAP_PROP_POS_FRAMES, 300)
rval, frame_1 = vc.read()
rval, frame_2 = vc.read()
frame_1_gray = cv2.cvtColor(frame_1, cv2.COLOR_BGR2GRAY)
frame_2_gray = cv2.cvtColor(frame_2, cv2.COLOR_BGR2GRAY)
计算光流的第一步要获取图像的关键点,这些关键点将作为追踪运动情况的标靶,这里对于关键点的检测可以指定一个mask蒙版,检测时只检测蒙版内的区域。可以作为一个粗筛手段,避免背景干扰。这个mask可以在UI界面里做成一个根据左边图像栏自己制定区域的功能。
feature_params = dict(maxCorners=20,
qualityLevel=0.3,
minDistance=3,
blockSize=5)
mask = np.zeros((frame_height, frame_width), dtype='uint8')
mask[frame_height//2:frame_height//2+600, position-300:position+300] = 1
p0 = cv2.goodFeaturesToTrack(frame_1_gray, mask=mask, **feature_params)
然后计算光流,得到匹配的关键点good_new和good_old
lk_params = dict(winSize=(15,15),
maxLevel=5,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
p1, st, err = cv2.calcOpticalFlowPyrLK(frame_1_gray, frame_2_gray, p0, None, **lk_params)
good_new = p1[st==1]
good_old = p0[st==1]
画出来一下看看究竟对不对
line = np.zeros_like(frame_1)
frame = frame_overlay
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
line = cv2.line(line, (a,b), (c,d), [0,255,255], 1)
frame = cv2.circle(frame, (a,b), 3, [0,0,255], -1)
frame = cv2.circle(frame, (c,d), 3, [0,255,0], -1)
img = cv2.add(frame, line)
cv2.imwrite('optical_flow.jpg', img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
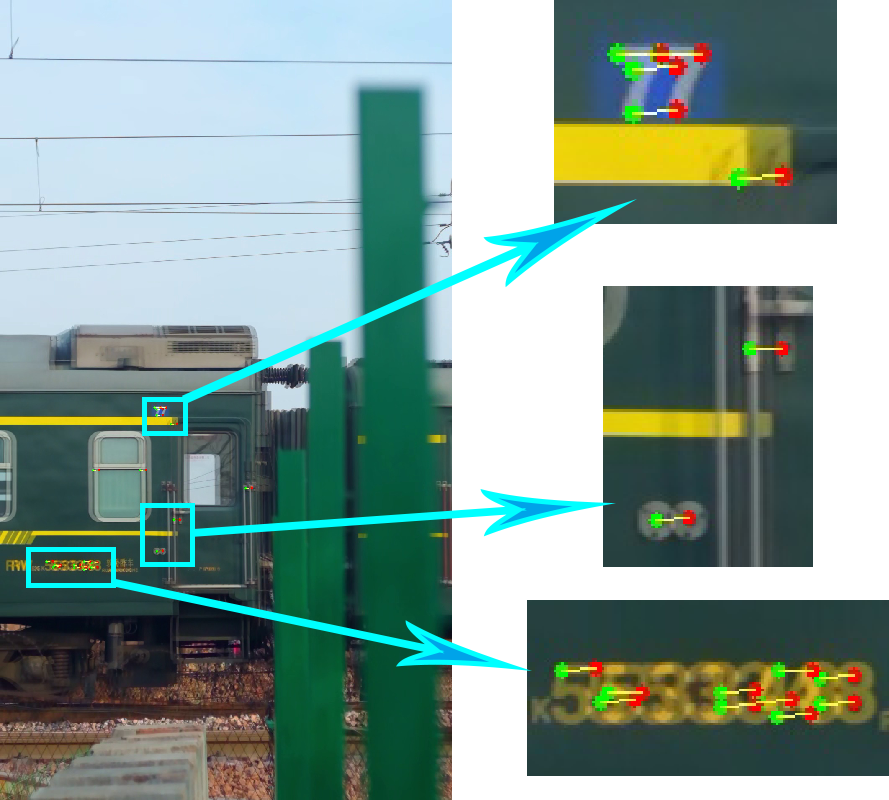
这时,我们计算good_new和good_old之间在x轴上的差值,就能获得运动的距离,但是由于偶尔会有干扰点或者误差点,所以我们直接取这一堆数里的众数,作为实际的运动距离。
moving_distance = [int(good_new[i, 0]-good_old[i, 0]) for i in range(len(good_new)) if abs(good_new[i, 1]-good_old[i, 1]) < 2]
width = max(moving_distance, default=None, key=lambda v: moving_distance.count(v))
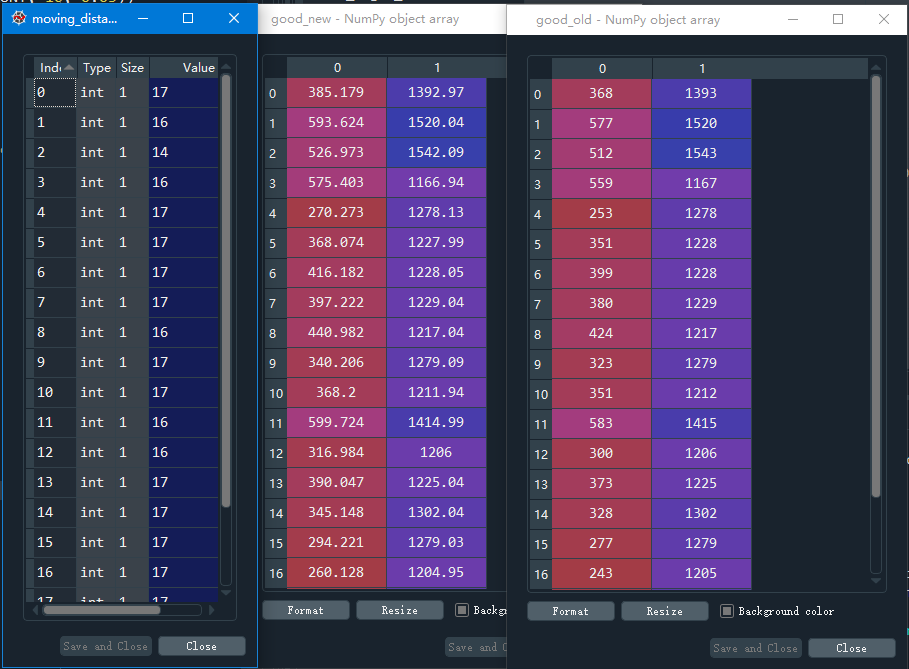
这个差值如果是正值则代表后一帧在前一帧的右边,那么运动距离就是从左到右,是负值的话就反之。这个正负就可以作为运动方向的判断。
由于这里用到的是不定的width,所以拼接图时有两种方法可选择:一种是动态地拼接图片,这个好处是程序简单,缺点是非常慢,尤其在图片越拼越大之后。一个10000多帧的录像,老潘洗完澡回来发现还没拼完。
所以不推荐上述方法,建议利用第二种方法,事先初始化一个空图片矩阵,这样的话,方法和上一版本的基本一致,唯一有大变样的地方在于计算正确的矩阵大小。也就是图片长度。
自适应检测运动间隔的大体思路如下:首先手动指定一个开始运动检测的第一个关键帧(避免开头无运动火车的影响),这个关键帧之前以及这个关键帧之后的一段内,width为此关键帧检测到的火车运动距离,往后有第二个检测关键帧,后续的一小段所用的width为第二关键帧检测到的火车运动距离,第三关键帧及以后同理。所以还需要指定一个检测灵敏度,这个灵敏度就是关键帧的数量,越多越能灵活应对变速情况。(灵敏度=1即只抽一帧进行速度检测,适合匀速情况,灵敏度=总帧数即每一帧都进行运动检测,适合蛇皮走位的极度复杂情况,但每帧都要计算光流会慢到爆),具体灵敏度可以根据上一篇里面1像素能够接纳的火车运动速度变化区间来指定。
窗口宽度为1像素,则火车速度就应该为6.83x60 mm/s,即0.41m/s。
这种情况下,火车在±0.41m/s内的速度变化并不会影响到当前的扫描区间结果。
具体计算时为了方便起见,利用列表来管理关键帧的位置和对应的运动速度(width),为了防止短时间内可能出现的检测误差情况,向后检测连续两次光流取均值获取更稳的结果。 在循环外又额外增加了一下img_length是因为adaptive_length//adaptive_sensitivity的整除可能会导致最后有几帧被遗漏,通过这一行可以修正img_length的数值。经过老潘的手动计算以及实际测试,这样的图片长度是刚好的。
img_length = 0
width_list = []
width_adjust_position = []
for i in range(adaptive_sensitivity):
print(adaptive_start + i * (adaptive_length//adaptive_sensitivity))
vc.set(cv2.CAP_PROP_POS_FRAMES, adaptive_start + i * (adaptive_length//adaptive_sensitivity))
rval, frame_1 = vc.read()
rval, frame_2 = vc.read()
rval, frame_3 = vc.read()
width_list.append((optical_flow(frame_1, frame_2)+optical_flow(frame_2, frame_3))//2)
if i == 0:
img_length = width_list[0] * (adaptive_start + (adaptive_length//adaptive_sensitivity))
width_adjust_position.append(0)
else:
img_length += width_list[i] * (adaptive_length//adaptive_sensitivity)
width_adjust_position.append(adaptive_start + i * (adaptive_length//adaptive_sensitivity))
img_length += width_list[-1] * (adaptive_length - (adaptive_length//adaptive_sensitivity) * adaptive_sensitivity)
img = np.empty((frame_height, abs(img_length), 3), dtype='uint8')

之后还有一个难点是如何在遍历视频帧时知道当前处于哪个速度区间内?老潘想了一个鬼点子:利用当前帧的序号减关键帧的列表,统计列表里面值<=0的数量,这个数量-1,就应该是当前帧所对应的关键帧之间的速度区间。而且对于img的操作,pixel_start的计算逻辑也应该变一下,让他像指针一样跟随进度变化而改变自己的指向位置。
if width_list[0] > 0:
pixel_start = img_length
for i in range(total_frames):
rval, frame = vc.read()
if not rval:
print('break')
break
width = width_list[((width_adjust_position - i) <= 0).sum() -1]
pixel_start -= width
pixel_end = pixel_start + width
img[:, pixel_start:pixel_end, :] = frame[:, position:position + width, :]
if i % 100 == 0:
print('{}/{} - {}'.format(i, total_frames, width))
如果速度为负则反之,和上述大同小异,只是指针变化情况稍微变一下:
else:
pixel_start = 0
for i in range(total_frames):
rval, frame = vc.read()
if not rval:
print('break')
break
width = abs(width_list[((width_adjust_position - i) <= 0).sum() -1])
pixel_end = pixel_start + width
img[:, pixel_start:pixel_end, :] = frame[:, position:position + width, :]
pixel_start += width
if i % 100 == 0:
print('{}/{} - {}'.format(i, total_frames, width))
上一版本的图像保存可以直接用,但是由于获取图像长度的方法不太好,这一版本里改为img.shape[1]获取图片长度,替换原本的什么帧数乘width的复杂操作。
之后将这些功能整合到原本的UI程序里面。加一下控件互动(代码略,可自行阅读源码),修改后的布局界面如下,选择manual或者adaptive则会使用对应功能的值,另一部分的值不会起作用。
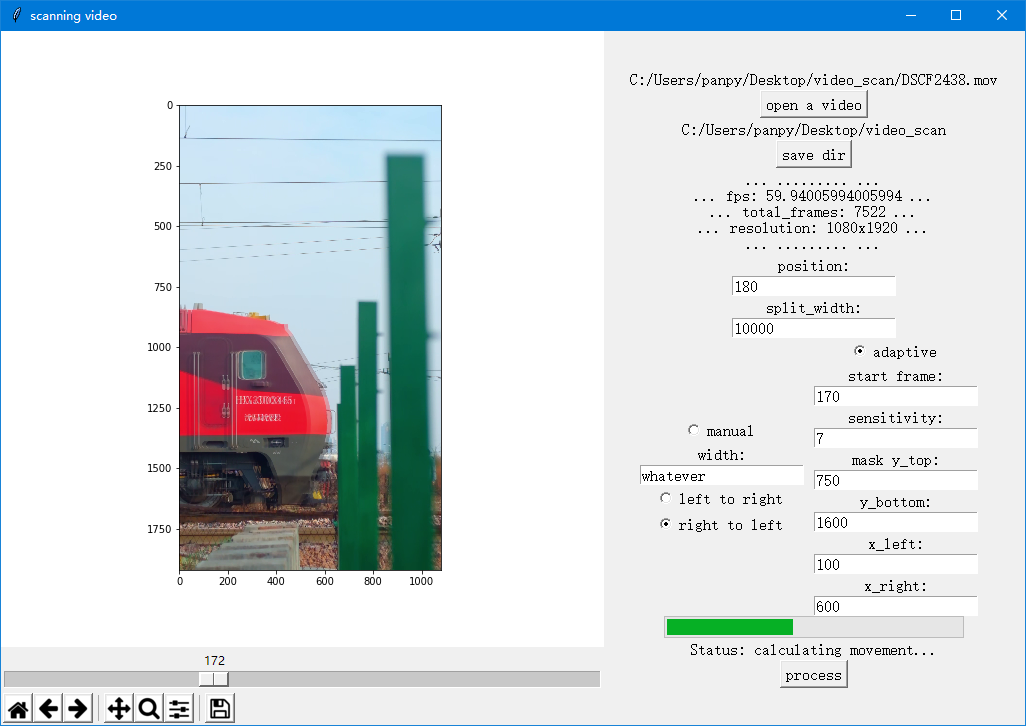

至于识别的准确率,准起来比老潘手动去数格子都要准,但是偶尔也会有识别失误的情况,根据多次测试,这种情况是mask没有很好罩住车体,有一部分干扰前景或背景(例如行人的走动、草木被风吹动)影响了被检测的运动点。此时调整mask的范围,即可解决。
