硬币系列二 | 从照片中自动检测硬币

最近搞了一些稀奇硬币,老潘把他们都用手机拍了下来。但是由于手机镜头焦距所限,并不能让硬币充满整个画面。所以很自然的想法就是,把硬币从图片中裁剪出来。一个正常人的做法是,把需要拍摄特写的物品放在纯净颜色的背景上,这种做法其实也有利于后期的抠图。
但是,我们希望将图片的外围裁剪到刚好框住硬币,不多余也不遗漏。或者说,做出硬币轮廓的外接矩形。我们可以选择用手一个一个的裁剪。
但是老潘是很懒的人,能躺着办绝不坐着办。打开电脑,拿起键盘,启动你最爱的IDE。
首先,小学美术课上应该有教过图像的边缘提取方法。目前比较主流且效果比较好的方法是Canny算子法,这种方法主要通过以下步骤得到一幅图片的边缘线条:
-
将图片高斯模糊,消除噪声影响,一般用3x3或者5x5即可。
-
计算上下左右方向的图像梯度信息(理解为计算当前点和周围点的明暗高低关系即可),这时候,如果这个点左右两边都和该点亮度差异很大,这就证明这个点在图形边缘上,反之,没什么差异证明这个点在一马平川上。
-
再进行非极大值抑制(把不是最大值的点抑制下去)。对步骤2得到的梯度信息,再观察一个点和周围点的高低关系,对于最大值点保留其值,比他小的点赋予0。
-
通过双阈值得到最终的边界图像。对上面步骤得到的图像,再次进行判断:给定一个上下界,高于上界的值作为强边缘,低于下界的值为弱边缘,夹在上下界中间的,如果这个点附近一圈存在强边缘,也把这个点作为强边缘。最终只保留强边缘作为最终的边缘图像。
关于canny边缘检测的理论结合实践部分,这篇博客很好:https://www.cnblogs.com/mmmmc/p/10524640.html
通过openCV可以使用以下方法快速得到一幅图片的轮廓信息
img = cv2.imread(apath)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (3, 3), 0)
thresh = cv2.Canny(gray, 10, 100)
这里的例子如图所示,一个硬币和利用这种方法提取出的硬币边缘线条。

这时候,我们可以选择直接作出图中颜色为白色区域的外接矩形,如果一切正常,那么面积最大的那个矩形就会是硬币的外轮廓。(背景如果不是纯色就可能会导致轮廓混杂粘连),图中将这些外接矩形用蓝色标记到了原图上。
通过以下方法可以获得一个0-1二值图中的白色区域边界信息
_, contours, hierarchy =cv2.findContours(closed, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
之后对这个边界信息做外接矩形并且保留面积最大的矩形。为了防止出现其他面积更大但是奇奇怪怪的轮廓,需要限制这个区域的长宽比不可以差太多,这样选出的框基本就是硬币主体了。
max_area = 0
for cnt in contours:
x, y, w, h =cv2.boundingRect(cnt)
cv2.rectangle(img,(x, y), (x + w, y + h), (255, 0, 0), 2)
if w*h > max_area and 0.8 < w/h < 1.25:
max_area = w*h
rec_x = x
rec_y = y
rec_w = w
rec_h = h
img = img[rec_y:rec_y+rec_h,rec_x:rec_x+rec_w]
可以看到由于我的背景有其他的杂物和纹理,所以被标记了很多其他的区域。但是能够符合面积最大并且长宽比不差太多的只有中间这个硬币。

但是实际这么做的话会有一个问题,硬币的最外圈边缘有可能断裂开。这样,图片中白色区域的外接矩形就会出现问题。

事实上经过测试,由于这个问题造成的裁剪错误有不少,所以应该在提取边缘之后再搞点什么动作。
众所周知,形态学处理可以对图像的这种残缺进行处理,比如说人尽皆知的开闭操作,可以对这种提取了边缘的边缘图像进一步对缺口进行连接,或者对噪点进行消除。而开闭操作又是由腐蚀和膨胀组合形成的操作,腐蚀是利用一个小的形状(术语叫结构元)对图像一点点扫描下去,只要结构元和图像白色区域没有完全重合,就把这个结构元的判别点(一般是结构元中心)下面的颜色变成黑色。膨胀相反,只要结构元和图像的白色区域有一点点重合,就把判别点下面的颜色变白。
图像中的白色小杂点不可能和结构元完全重合,腐蚀可以让杂点被抹去。膨胀可以让图像白色区域胖起来,缝隙就会渐渐挤在一起连起来了。这里老潘闲的做了个动图,展示了一个图像提取了轮廓之后膨胀了5次,腐蚀了10次,又膨胀了5次的过程。图中可以看到,膨胀5次使硬币的轮廓完全清晰可见了,腐蚀则是将由于膨胀造成的轮廓变大再缩回去。另外再腐蚀将背景的杂点去掉,由于腐蚀又造成了轮廓缩水所以还要再膨胀回来。最后的图中仅剩的圆形刚好就是硬币的外轮廓。这时候,先膨胀5次又腐蚀5次就对应了闭操作,后又腐蚀5次再膨胀5次对应了开操作。图中也可以看到,使用的结构元的形状是方形。
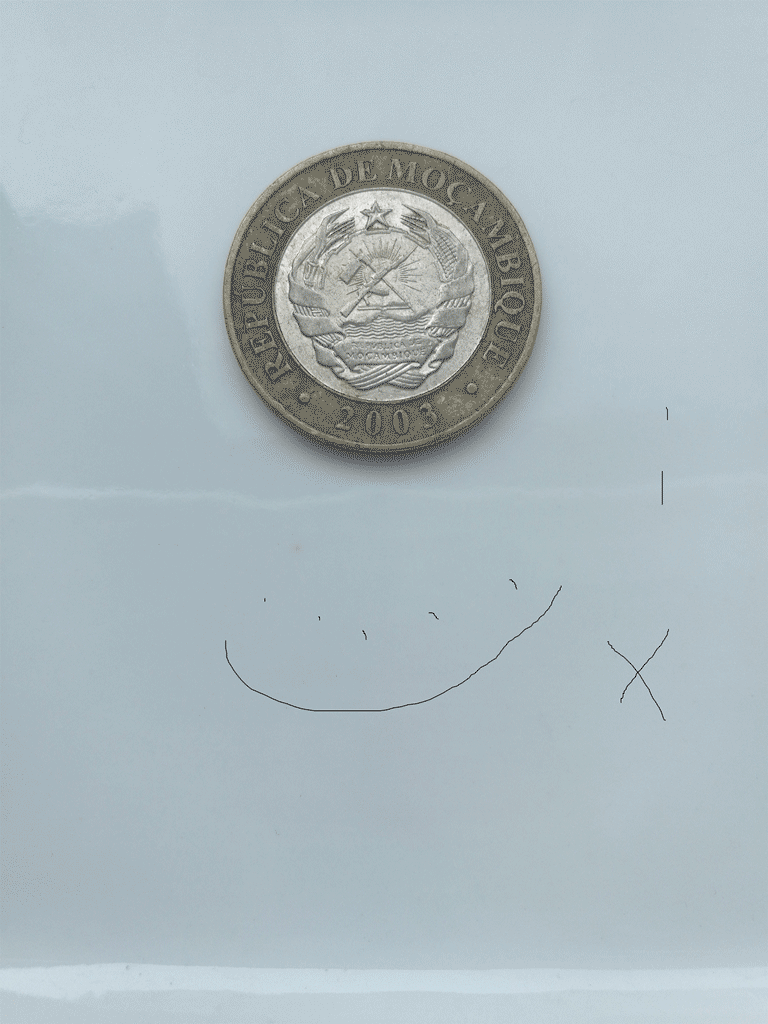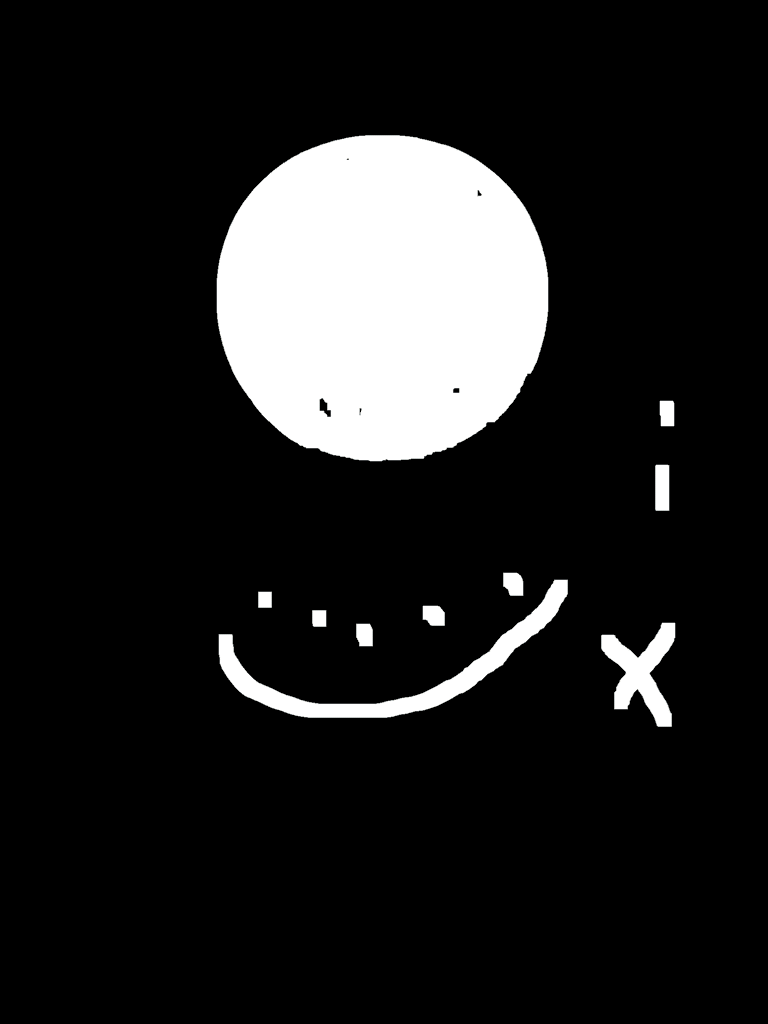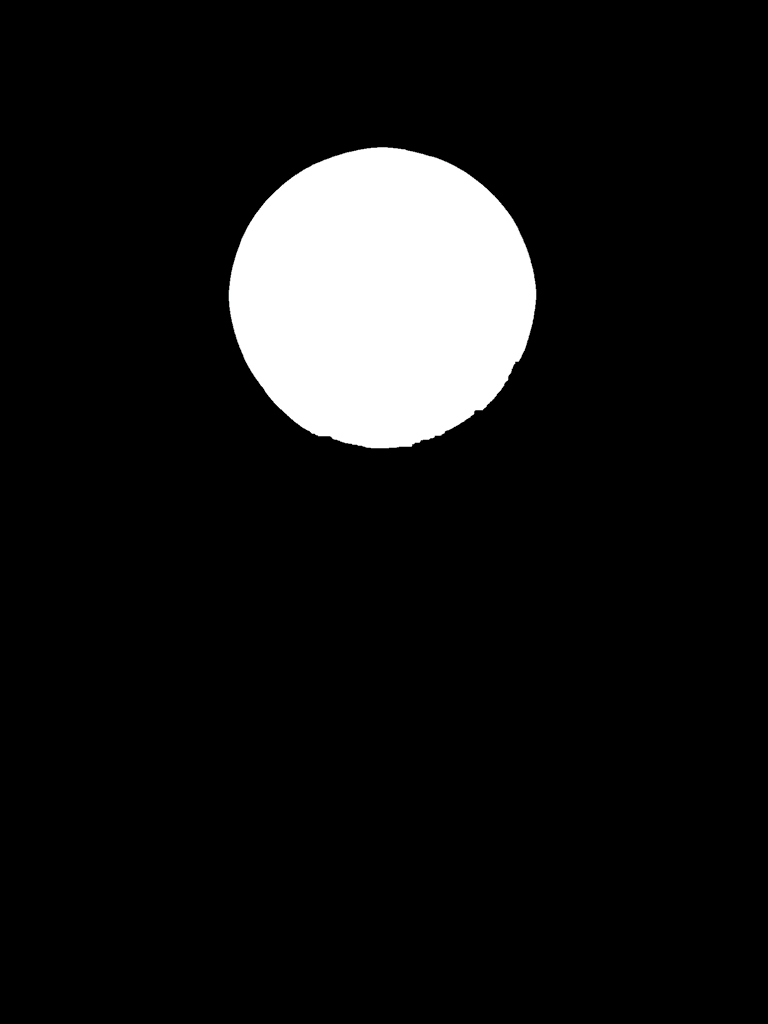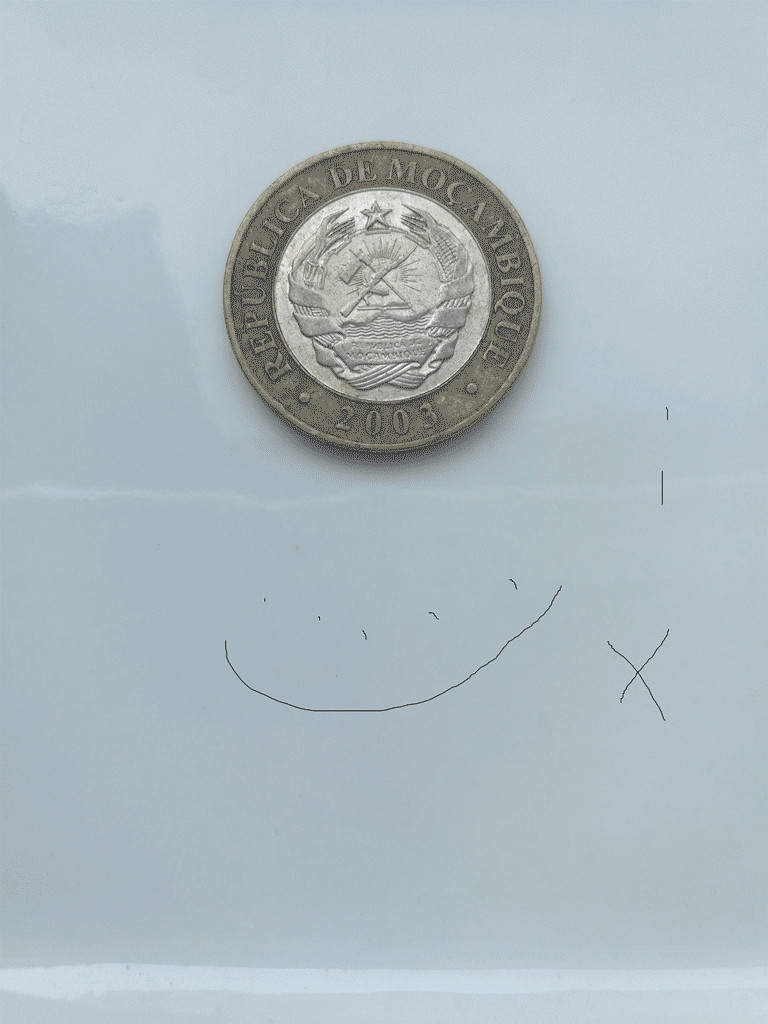
通过这样一顿操作,可以获得非常可靠的硬币外轮廓信息了,对这时候的图再提取白色区域的外接矩形就不会出现硬币断开的情况。对图像进行腐蚀膨胀开闭操作的方法如下:
kernel =cv2.getStructuringElement(cv2.MORPH_RECT, (9, 9))
thresh = cv2.dilate(thresh, kernel)
thresh = cv2.erode(thresh, kernel)
closed = cv2.morphologyEx(thresh,cv2.MORPH_CLOSE, kernel, iterations=5)
opened = cv2.morphologyEx(closed,cv2.MORPH_OPEN, kernel, iterations=5)
对比一下只用canny边缘提取做外接矩形和进行闭操作以后的外接矩形差异,优化前对应着前面提到的边缘断开造成的外围最大的外接矩形错误,可以看到优化前的轮廓非常混乱,因为每一个白色的边缘线条都会被当做一个独立连通区域去框定他的外接矩形。优化后硬币主体对应的连通区域一般就是一个圆了,边界也非常干净简单。

如果看一下优化后,用来做外接矩形的白色区域长什么样子,如下图所示是几个硬币的canny边缘图像闭操作以后的结果。虽然硬币范围内有孔洞,但是不会影响整个区域的外轮廓,外接矩形仍然可以死死卡在圆周上。在边缘上的孔洞看似可能会导致区域有缺口,但是由于闭运算的特性,实际上仍然会有1像素宽度的线包裹着他,而且最外围的细外轮廓线不太可能再有断裂了。
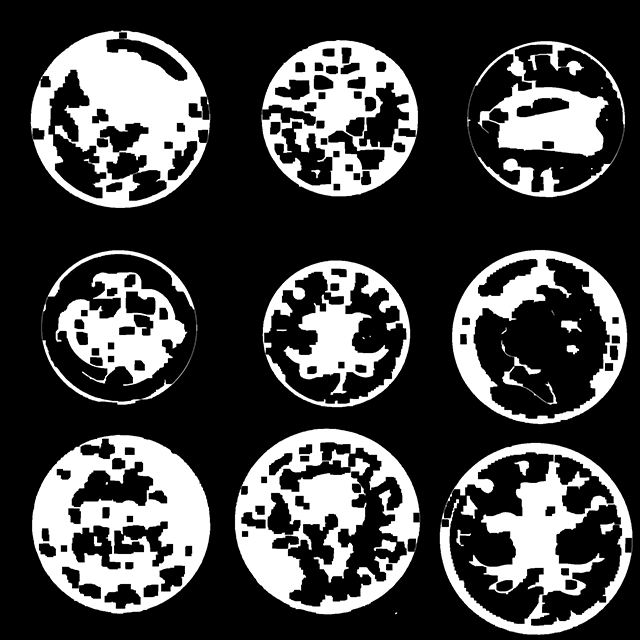
通过以上操作已经可以完美的将硬币裁切出来了。这就是关于硬币图像裁剪边缘检测的方法了,你学废了吗?欢迎在评论区告诉小编一起讨论哦!
后来在查阅论文和各路资料的时候发现,有一种叫做霍夫变换的方法可以直接检测图中的圆形区域,我没有试验这个算法的效果,而且老潘偏偏有几个不是圆形的硬币,我不知道霍夫变换面对这种方形和花花形硬币效果如何。
后记:既然都提到了那就试一下,我发现霍夫变换速度好慢,还会把CPU全部占满。(图太大的话就会很慢)
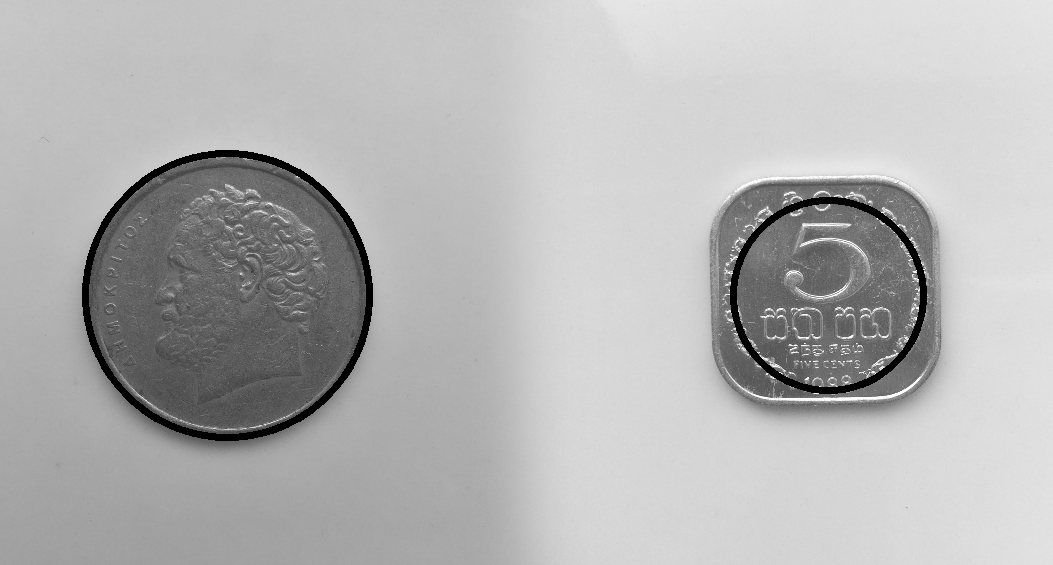
做这个事情并不仅仅是想要把图像剪出来这么简单。如果想要查询每个硬币对应的来历、材质、等等信息,简直让人一头雾水,尤其某些硬币上面完全没有英文,查都不知道怎么查。那么能不能让电脑帮帮我,直接给他图让他帮我查呢?

经过一番折腾,老潘发现一个网站可以直接传图,以图识图,给你这个硬币的信息。当然这都是后话,我折腾了一圈,尝试了多种图案比对方法均无果以后,发现自己走了个远路,原来这有网站可以直接用啊,准确率也还可以。不过由于上传图片需要将图裁到只包含硬币,那其实还是要用到我前半部分做的图片裁剪。
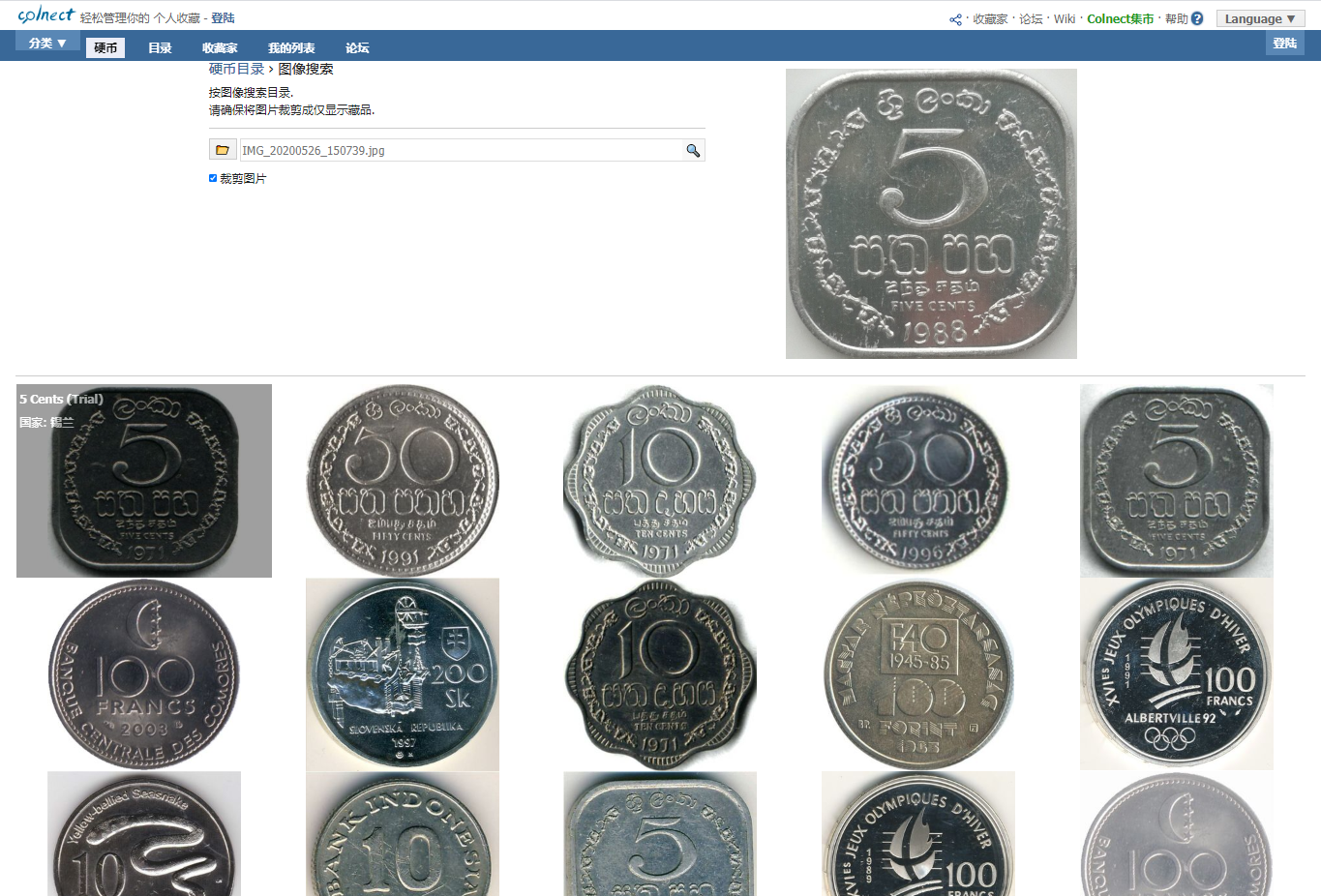
反正折腾也折腾了,留下一些折腾的成果吧,指不定什么时候还能再用上。
首先是爬虫这个一上来就爬废了,我初步的设计是,到一个硬币图鉴网站上(网址:https://zh-cn.ucoin.net/catalog)按照他清晰良好的层层结构,把所有有图为证的硬币图片全部抓下来,抓的同时,记录下这个硬币的文件名,以及这个图所在的硬币详情页链接地址,存进一个表里。在做比对的时候可以让程序自动找到和待测硬币最相似的标准硬币,照着标准图片的名字找到对应页面再去打开这个页面,完成自动化硬币信息查询。
实验设计无比巧妙,刚开始第一次requests.get的时候发现返回来的HTML里面没内容,解析一下文本发现403,于是想到可能是这种直连会被挡。加一个伪装,设置一个header即可,这样可以把发出来的请求伪装成是普通浏览器发出的请求。设置方法如下
# reference:https://blog.csdn.net/jamesaonier/article/details/89003053
agentPools = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML,like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, likeGecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16(KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10)Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208Firefox/2.0.0 Opera 9.50"
]
headers = {'User-Agent':random.choice(agentPools)}
res = requests.get(index_url,headers=headers)
之后就能连上了,前期小规模爬测的时候毫无问题,眼看着一级目录已经建好(一级目录是所有的国家地区分类链接),二级目录也捋顺了(二级是每个国家地区下面的年份和硬币币别),三级目录就是每个硬币对应的详细页面和图片,这也都没有问题。于是火力全开去挂机。
挂到一半发现没图了,测试发现返回来的HTML里没有对应的链接了,输出一下文本一看是我IP被ban了。好,看来这个网站比百度老狗要严密一些。那我就用IP池吧。结果自此开始掉入深坑。用国内的各种IP去连,速度都巨慢而且容易断线。用科学上网连接很快,但是无法自动化更换IP,而且爬不超过半小时就会把IP再次ban掉,我甚至已经设置了每次请求sleep5秒,无济于事,可以说这个反爬让老潘有点下不去手。
设置代理IP的方法如下
with open('./ip.txt', 'r') as f:
ip_pool = f.readlines()
def get_proxy():
#获取IP文本的方法很多,可上网自查
#或去看我的完整工程文件里有一些说明注释
r= random.choice(ip_pool).strip('\n')
proxy = {'https': r}
return proxy
res = requests.get(index_url,proxies=get_proxy(), headers=headers)

爬虫到此为止,只爬到了几百个硬币就弄不下去了心态崩了。如果有经验丰富大佬指点我爬完全站,老潘给你投币三连这次一定。
下一篇讲解如何检测相似的硬币。这篇有点长了,分开成两篇发又可以多水一篇推送美吱吱
源码和下一篇合在一起了,都在GitHub