再进阶 | 利用生成式对抗网络自动生成猫咪图片
文中所有用到的代码在github中
本次项目运行环境为Python3.6.8 + PyTorch1.1.0
书接上回,我们已经可以通过爬虫海量获取想要的图片,也可以通过神经网络对图片筛选分类了。拿到这么多图片之后,还有没有进一步发挥的空间?要是没有我就删掉了这么多校花图片说删就删?我们为何不用这些图片,再次输入另外的神经网络,让电脑自动无穷无尽的为我们源源不断输出符合我们口味的菜呢?

生成式对抗网络(Generative Adversarial Networks, GAN)是一种非常有趣的神经网络。它可以学习到某一种映射规律,从而将某种输入的信号变换成另一种信号。
当我们使用图片分类那次所用到的网络时,我们给了网络一个图片,让它判断这是猫还是狗。
这个过程其实是从众多的信息里提取出某一种共性信息,即数据降维的过程。本质是丢弃无用信息。
但是这个任务如果反过来呢?当一个智力阅历正常的成年人,看到“猫”,就能想象出某一种毛乎乎的,圆头,带尾巴,甚至一些其他特征的动物。但对于计算机来讲,这种“脑补”的任务却很难做到。

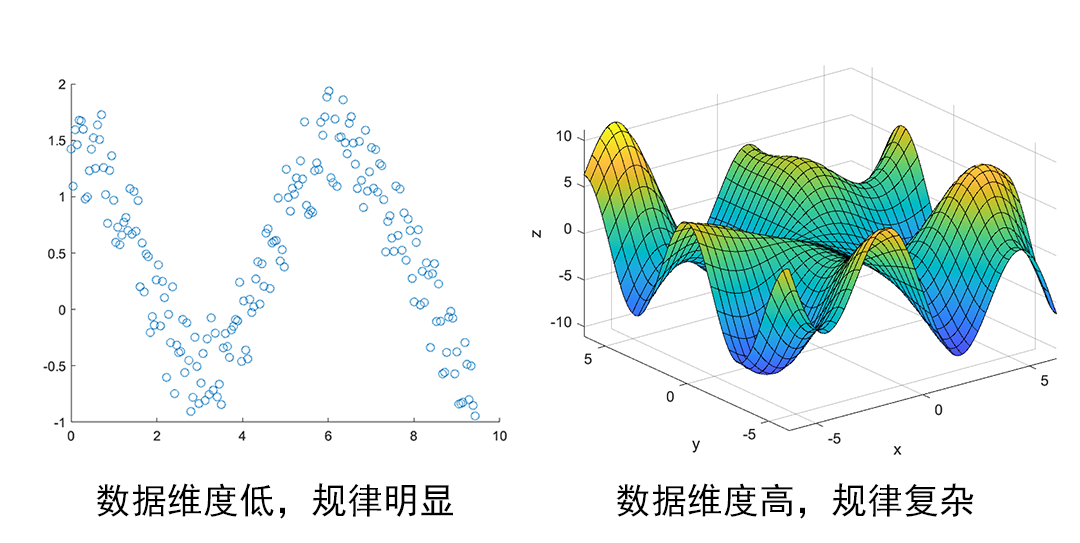
如果是一组二维数据,散点大致符合某种形态,即使不用神经网络,肉眼都能大致看出来他们之间符合的规律,此时如果要推断不存在的新点位,可以按照规律生成,甚至可以给出可信度很高的概率密度表达式(显式密度模型explicit density model),一旦有了表达式,计算机便可以无休止的进行数据的预测。然而当数据维度很高时,这个规律很难找,表达式更难得出,让计算机在没有数学表达式的情况下预测一个值将变得很难。猫的种类、耳朵形状、毛色等组合有千万种,每个种类从每个角度看也有千万形态更何况猫是流体,想要仅靠“猫”一个初始自变量就想象出其他的因变量,难点主要在于数据涉及范围的维度太高,很难得到准确的数据分布关系。用已知信息做预测时缺失的信息量太大,如窥一斑而见全豹,这斑有可能是豹子身上的,也可能是你女朋友的豹纹短裙上的。
既然用数学表达式直接代入计算的方法已经不可行了,不如直接让神经网络从一些输入出发,随机生成一些图片,一次次告诉这个网络距离真实数据还有多大差距,使神经网络向缩短差距的方向继续改进输出结果,步步为营,通过不断试错生成差距足够小,足够逼真的结果(隐式密度模型implicit density model)。至于监督输出结果,如果用人工方式操作未免太麻烦,不如同时让另一个神经网络学习分辨真假,以此来监督他。于是生成对抗网络就出现了。此时我站在上帝视角来看,这个网络内部发生着如下过程[1]:
- 生成器先拿了一个画了很多线框的幼儿填色本随便填了一些颜色,由于生成器现在什么都不知道,画的花花绿绿惨不忍睹。
- 我同时把正确的猫图片、生成器画的东西给判别器看了,并且告诉他,哪个是真的哪个是假的(判别器梯度更新),这时判别器学习到了这个区别。(判别器权重更新)
- 生成器又拿了一个填色本画了一遍。
- 第二天我把判别器叫过来,展示了生成器的画,并且我给判别器说这是真猫,判别器根据自己昨天学到的知识,看了之后大骂生成器,说“你画了个什么玩意儿,这根本不是真猫,真猫没有绿色的。”(生成器梯度更新)
- 生成器这次学到了真猫没有绿的,下次画画不用绿颜色了。(生成器权重更新)
1-5步就这样循环几百万年之后,生成器已经知道了很多让填色画像猫的技巧了,判别器也学会了很多辨别真猫和假画的技巧了,这时候进行最后一轮较量:
- 生成器拿来填色本,由于已经是个成熟的神经网络了,所以他画了一个和真猫别无二致的猫。
- 我同时把正确的猫图片、生成器画的东西给判别器看了,并且告诉他,哪个是真的哪个是假的,这时判别器学习到了这个区别。
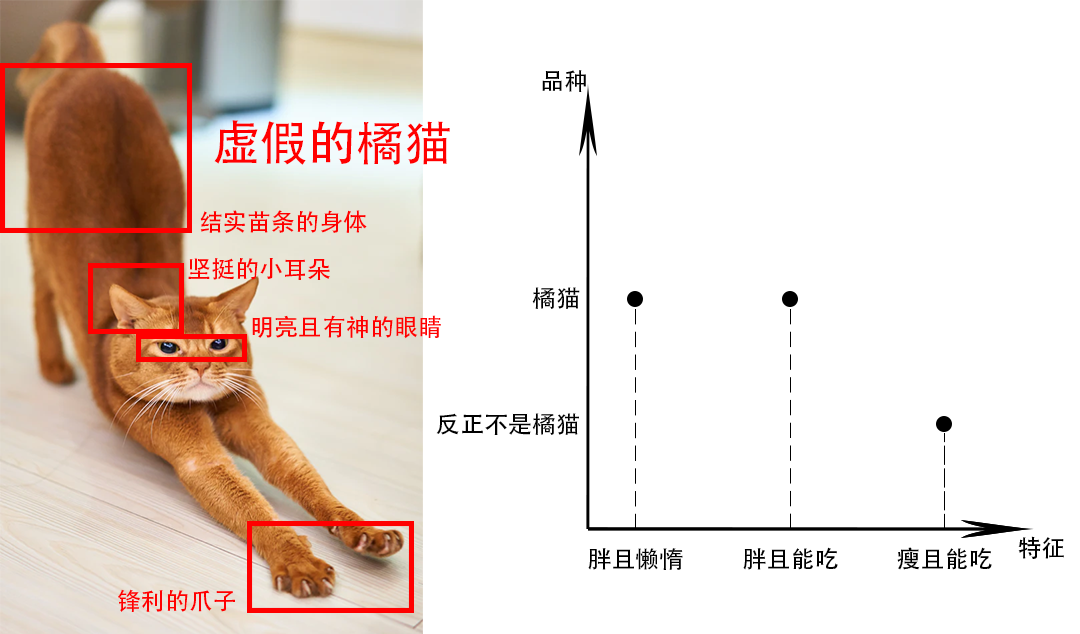
- 生成器又画了一只橘黄色的猫。
- 第二天我把判别器叫过来,展示了生成器的画,并且我给判别器说这是真猫,判别器看了之后,竟然挑不出毛病,说“这确实是个真猫,但是橘猫貌似没有这么瘦的?”
- 生成器这次学到了下次画橘猫可以画再胖一些,但是其他地方就不用费神去修改了。
其实网上很多什么假画作家与收藏家、侦探和罪犯之类的比喻,虽然贴切但是一直没有触及到具体的细节,其实这里的细节与这些比喻还是略有不同。生成器产生的数据,给判别器学习的时候是归为假数据标签,而让生成器学习时则归为真数据,用判别器判断的误差作为生成器的损失函数。(拿着假数据硬要判成真数据,误差当然大了。让假数据判真的误差变小的过程,就是生成器学习的过程。)
通过代码来实现以下上面的步骤吧,顺便看看中间会不会有什么细节问题。首先老潘从网络上找到一个生成动漫头像的GAN网络实例[2],先拿过来配置部署一下,看看能不能稍后改造一番,为我所用。
经过一番审视,这个代码用到的GAN结构就是大名鼎鼎的DCGAN(Deep Convolutional GAN)[3],其中的训练过程就是上面这个思路的实现(代码略有精简以便理解):
true_labels = torch.ones(opt.batch_size).to(device)
fake_labels = torch.zeros(opt.batch_size).to(device)
noises = torch.randn(opt.batch_size, opt.nz, 1, 1).to(device)
for epoch in range(epochs):
for i, img in enumerate(dataloader):
real_img = img[0].to(device) # dataloader是个列表,第一列是图片,第二列是类别
# 训练判别器
optimize_d.zero_grad()
# 学习分辨真图
real_out = netd(real_img)
error_d_real = loss_func(real_out, true_labels)
error_d_real.backward()
# 学习分辨假图
noises = noises.to(device)
fake_image = netg(noises)
fake_out = netd(fake_image.detach())
error_d_fake = loss_func(fake_out, fake_labels)
error_d_fake.backward()
optimize_d.step()
# 两个loss越小代表判别器越能准确判真假
# 训练生成器
optimize_g.zero_grad()
noises.data.copy_(torch.randn(opt.batch_size, opt.nz, 1, 1))
fake_image = netg(noises)
output = netd(fake_image)
# 用假图判真的误差作为loss
# loss越小代表判别器越不能分辨结果真假
error_g = loss_func(output, true_labels)
error_g.backward()
optimize_g.step()
这里涉及的是对网络的训练部分,至于里面的netd和netg则分别代表判别器(discriminator)和生成器(generator)。DCGAN网络构成如下:
class NetD(nn.Module):
# 构建一个判别器,相当与一个二分类问题, 生成一个值
def __init__(self):
super(NetD, self).__init__()
ndf = opt.ndf
self.main = nn.Sequential(
# 输入96*96*3
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# 输入32*32*ndf
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, True),
# 输入16*16*ndf*2
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, True),
# 输入为8*8*ndf*4
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, True),
# 输入为4*4*ndf*8
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=True),
nn.Sigmoid() # 分类问题
)
def forward(self, x):
return self.main(x).view(-1)
判别器NetD是一个将图片一步步卷积池化(这个人用步长卷积代替池化了)将图片降维成一个数值,用sigmoid层把数据缩放到[0, 1]之间,进行二分类。其中Conv2d具体参数意义[4]为
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
class NetG(nn.Module):
# 定义一个生成模型,通过输入噪声来产生一张图片
def __init__(self):
super(NetG, self).__init__()
ngf = opt.ngf
self.main = nn.Sequential(
# 假定输入为一张1*1*opt.nz维的数据(opt.nz维的向量)
nn.ConvTranspose2d(opt.nz , ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(inplace=True),
# 输入一个4*4*ngf*8
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输入一个8*8*ngf*4
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=True),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输入一个16*16*ngf*2
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(inplace=True),
# 输入一个32*32*ngf
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh()
# 输出一张96*96*3
)
def forward(self, x):
return self.main(x)
生成器NetG是一个反向的操作,利用一组随机值,通过学到的某种变换手法,将这些值反卷积,层层扩大,脑补出输入数组到输出图像这中间的数值变换规律(这个规律极其复杂并且常人无法理解),最后用tanh层将图像数据缩放到[-1, 1]范围内。其中ConvTranspose2d具体参数意义[3]为
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')
先试一试到底能不能成,首先利用少量的动漫头像文件做一下初步测试,老潘从网络上随便找来了25个动漫头像图片,放在某个文件夹中,通过以下方法将数据读取进来并且预处理[5]一下:

dataset = datasets.ImageFolder(r"img/train/anim", # 这个路径下必须还有一层目录,对应着图片的分类
# 由于这次不需要分类所以随便再套一层目录就行了
transform=transforms.Compose([
# 要用transforms.Resize([224, 224]), 不能写成transforms.Resize(224),
# transforms.Resize(224)表示把图像的短边统一为224,另外一边做同样倍率缩放,不一定为224
transforms.Resize([opt.img_size, opt.img_size]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()]))
dataloader = DataLoader(dataset,
batch_size=opt.batch_size,
shuffle=True,
drop_last=True) # 事先初始化了标签的数量是batchsize,落单的数据少于batchsize
先运行一下看看能不能正常运行

嗯有点内味了。能看出来从一开始的乱噪声,变成了隐隐约约仿佛有一些二次元的脑袋,只不过这个次元壁好像有点扭曲。(一组25个生成结果放在了一个结果图里)
但是由于训练次数少,供参考比对的图片数量也少,所以生成的结果中要么非常混乱(如右边上下角的结果),要么出现了一些固定的模式(如在多个结果里出现相同的千寻轮廓)。

行了,回归标题,用收集好的大量数据对这个网络进行训练试试。一开始老潘找了LSUN数据集[6]里的猫猫目录,总共42GB,但是觉得数据太多了可能会压垮我们的玩具级项目其实最主要是老潘折腾半天搞不明白他这个.mdb文件怎么解出图片来,所以老潘用了一些小一点的数据集来做,一个是百度上的猫脸识别[7],一个是kaggle猫狗大战[8]的猫部分图片。

先直接用原先的网络和训练方案做一遍试试。其中数据预处理部分略有变化。因为相比于原来动漫头像都是方形,现在的图片长宽比更多样,如果想裁剪成正方形并且缩小的话,需要使用transforms.RandomResizedCrop取代原本的transforms.Resize,这样可以不改变原图长宽比的前提下进行指定尺寸的裁剪:
dataset = datasets.ImageFolder(r"img/train/cat",
transform=transforms.Compose([transforms.RandomResizedCrop(opt.img_size,
scale=(0.9, 1.0),
ratio=(0.9, 1.1)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()]))
关于transforms.RandomResizedCrop的参数[5]是一个非常令人困扰的地方,interpolation是插值方法这个显而易见,但是中间那两个实在是令人摸不到头脑:
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.33), interpolation=2)
· size – expected output size of each edge
· scale – range of size of the origin size cropped
· ratio – range of aspect ratio of the origin aspect ratio cropped
· interpolation – Default: PIL.Image.BILINEAR
反正老潘看了好几遍解释是没看明白,试一下吧
RandomResizedCrop(224, scale=(0.3, 0.7),ratio=(0.5, 2))

RandomResizedCrop(224, scale=(0.9, 1.5),ratio=(0.5, 2))

RandomResizedCrop(224, scale=(0.5, 1.5),ratio=(1, 1))

原图

参数scale控制着裁切的部分的面积占原图的比例,同时裁切的范围不会超出图中最短的边。ratio控制着裁切框的长宽比例范围,如果长宽比导致比例超出scale设置的范围,则优先满足scale。最后将裁切的图重新放缩到size所指定的大小。
跑题跑的有点远。来看一下换了猫数据集训练的结果表现如何

随着运行时间增加,可以大致看出,生成器从噪声图片慢慢过渡到了某种组合模式,如果仔细看一下第36轮的结果

倒是大概能看出来中间有一团毛皮覆盖的东西,但是距离我们认知范围内的猫还有一定的差距。我觉得没有差距因为猫是流体,实验可以结束了本文完。当我们再仔细观察这幅图的时候,可以看到偶尔出现的固定颜色搭配和脸轮廓或者耳朵轮廓(没有出现绿色的毛色或者正方形的猫耳朵),只是在这些要素的排列组合上和常人有一丝不同。
当仔细审视这个程序的时候,老潘发现了一个问题,pytorch官方example[9]里面,在训练生成器时,直接用了训练判别器时生成的图片来做,减少一次生成器预测的时间。老潘试着在这个代码上修改成同样步骤,却发现生成结果一直模糊不清。

仔细审查之后发现,之前代码是在循环外给的随机数,然后在训练完判别器之后,随机数被更改,再把这个改变的随机数给生成器,生成一个结果。如果删掉这个,那么随机数将在整个训练中不变,导致数据量减少。从而收敛效果变差。将生成随机数的步骤挪到循环内部即可。小坑。程序写的坑。
还有一个小坑,输入图片的范围是[0, 1],生成器输出的图片范围是[-1, 1],给判别器时,可以把原图和假图都归到同样的范围,这样可以充分利用生成器tanh的取值范围。
训练时,可以根据进度调整学习率。从零开始时,进步空间很大,学习率可以适当大一些,多试错也没关系,但是后面成熟之后,就没有那么多犯错的机会了,这时候注意细节,一次取得一点小的进步才是比较稳妥的办法。在代码中设置一个学习率策略,并且每轮学习更新这个策略即可。
scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.9)
for epoch in range(epochs)
# train...
scheduler.step()
例如这里设置按照训练进度减少学习率,10个epoch,减小一次学习率,减小到原来的0.9
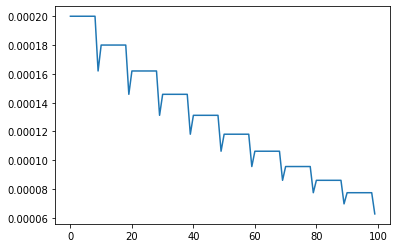
可以用optimizer.param_groups[0]['lr']获取当时的optimizer的学习率,例如将它放进print输出一下看看对不对劲。
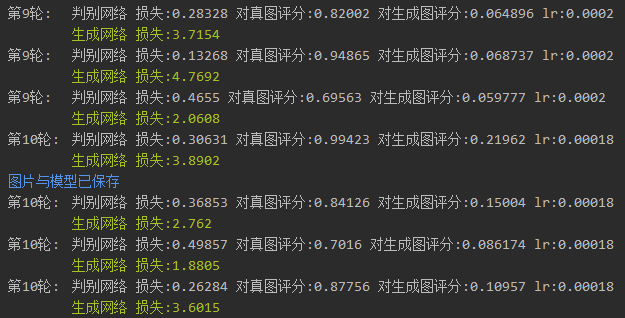
对比一下学习率衰减前后的结果。

可以看出,优化了学习率以后,输出结果高频通透,中频温润,低频有力,画面通透而不失空气感并不能看出明显差别,如果延长训练时间,效果应该会好一点,但是老潘没有强大的算力,不予在此纠结太长时间。
由于使用的数据集是给分类网络使用的,存在太多角度刁钻形态诡异的猫咪,给分类器可以提高泛化性,但是给GAN则难以在短时间内取得良好结果。老潘只想生成一些赏心悦目的猫咪,不想探究猫体在量子态下的时空相互性。所以像下面这种图最好还是剔除。只保留猫脸没有被挡住的并且占图像比例很大的部分,让GAN只学习生成猫脸,给他减负。

老潘是个懒人,能躺着办的事情就绝不坐着办,如何从这些数据中把猫脸裁出来,当然是用OpenCV来办。通过调用OpenCV已经做好的猫脸检测模型[10],再结合我们上一篇中用到的从目录读取图片批量操作的技术,可以一边午睡一边从数据集中截取[11]猫脸图片。当然OpenCV这个精度还是有限,所以他剪完之后还得再干预一下。这边用了个小技巧,为了扩大猫脸的外部范围,我把他的识别框边长分别以中心扩大了一倍。
img_id = 0
catface_cascade = cv2.CascadeClassifier('lbpcascade_frontalcatface.xml')
for maindir, subdir, file_name_list in os.walk('img/train/cat/'):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
img = cv2.imread(apath)
faces = catface_cascade.detectMultiScale(img, 1.1, 3, cv2.CASCADE_SCALE_IMAGE)
for (x, y, w, h) in faces:
face_img = img[x-w//2:x+w//2*3, y-h//2:y+h//2*3]
cv2.imwrite('img/train/catface/%d.jpg' %img_id, face_img)
img_id = img_id + 1
最终的数据集里面都是这样的。

使用清洗过的数据集再做一次训练。之前的程序里每次保存结果图片时,都用了一组新的随机数生成图片。按照惯例,我把它改成了固定随机数生成,以便观察网络收敛状态。体会一下GAN从随机乱输出,直到掌握一定套路输出的过程。

这是训练到230轮左右的生成结果。为什么这次训练轮数多了,因为仅截取猫脸使数据变少了,一轮训练的时间减少了。为什么数据变少了,因为OpenCV识别猫脸准确率不是太高……可以看出图中只保留猫脸时,相比于流体状态的猫,生成器能够更快速学习到正经猫的规律。

观察每轮结果,猫的五官每次都有变化,有时候好好的猫脸越变越奇怪,然后渐渐变成了另一个品种的猫。有时候猫眼睛一会儿大一会儿小。虽然这证明生成器在努力尝试让自己画的更像猫,但是改动有点大,反而让结果在震荡,不稳定。这时候尝试一下加入刚刚提到的学习率衰减策略,这次让他100轮减小一点,结果就有了一些好转,猫脸稳定了一些。

但是最终效果也没有那么明显,我看着最后的结果都差不多,毕竟总共就衰减了两次,而且一次衰减的量也不多,如果再增加一些训练时间,效果应该会不错。其实换一个RTX显卡就能快速完成实验不是吗?
再补充一个,如果训练时显存越占越多,最后OOM,可以尝试用以下方法清除无用缓存
torch.cuda.empty_cache()
参考文献:
[1] 一文读懂生成对抗网络(GANs)【下载PDF | 长文】:https://blog.csdn.net/qq_28168421/article/details/80993864
[2] 基于GAN的动漫头像生成:https://blog.csdn.net/qq_39086406/article/details/103274921
[3] A.Radford, L. Metz, and S. Chintala, “Unsupervised representation learning withdeep convolutional generative adversarial networks,” arXiv preprintarXiv:1511.06434, 2015.
[4] PyTorchDocs > torch.nn:https://pytorch.org/docs/stable/nn.html#conv2d
[5] PyTorch数据增强方法TORCHVISION.TRANSFORMS:https://pytorch.org/docs/master/torchvision/transforms.html
[6] LSUN数据集使用方法:https://github.com/fyu/lsun
[7] 猫脸识别-12种猫分类数据集:https://aistudio.baidu.com/aistudio/datasetDetail/10954
[8] Dogsvs. Cats | Kaggle:https://www.kaggle.com/c/dogs-vs-cats/data
[9] https://github.com/pytorch/examples/tree/master/dcgan
[10] https://github.com/opencv/opencv
[11] pythonopencv手动截取图片的部分区域并保存:https://blog.csdn.net/sinat_36811967/article/details/84853074
[12] Gui J, Sun Z, Wen Y, Tao D, Ye J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. arXiv preprint arXiv:2001.06937. 2020 Jan 20.