一个使用pytorch的图片分类教程——以明信片分类为例
本项目全部源代码地址:https://github.com/divertingPan/postcard_cls
前言
之前和师兄聊的时候随口说了一句,实验室应该留一点祖传的代码,这个“祖传”并不是贬义的那个含义,主要是指对于加载数据、调用模型、显示结果等等流程化的代码。每次拿到一个任务,如果都从头开始搞,势必效率很低,而GitHub上的代码又良莠不齐风格各异。如果能有一个比较成熟的流程化代码,这时有一个新任务,我们可以直接拿祖传代码改里面的dataset.py或者改net.py,而训练预测结果分析等等流程都可以直接用,或者很少的改动即可用。既然都说这么多了,那就自己搞一个吧,既方便自己也方便别人。
摘要
本次所用代码其实大部分也都是以前自己攒的乱七八糟的小模块堆起来的,只是一直没有一个系统的优化整理。借着这次机会,本文将从一个图像识别的任务入手,从数据的收集、清洗、预处理、读取、神经网络识别、自动超参数搜索、可视化分析、结果分析这几个方面一步一步介绍,最终完成一套整体的项目流程。
准备数据
炼丹最重要的事情是什么? 是要有丹啊!
首先要有原料,拿空气是炼不出来什么东西的。通常而言一个新算法搞出来,都是要在大家公认的标准数据集上做测试的,但是在实战中,总是要面对一些实际问题,这些问题的数据可能需要自己想办法获得,而炼丹所需要的数据量又挺大,所以收集数据(尤其是带标注的数据)就是一个大工程。
好在有一种技术叫爬虫,通过这种方法可以获得很多高质量的数据,前提是需要找到一个有你感兴趣数据的网站,并且这个网站的反爬机制又不是那么强,以及需要会爬虫。
这次项目用到的图片来自一个明信片网站,鉴于可能的版权或其他纠纷风险,这里不再对数据收集的详细过程做介绍。但是这个内容我写过,如果有实在非常感兴趣的同学,我相信他有能力找到我写的内容。
这里做一些通用的额外补充说明:爬虫最好挂在一个云服务器上,这样不用担心断电断网的风险(比起放在自己家电脑上),更重要的是,即使服务器IP被网站封了,也不影响你自己在家的正常使用(爬虫的另一个值得注意的点在于封号或者封IP的风险),而且如果需要模拟登录,请使用一个小号,不要傻乎乎拿自己的账号做。
下载完成后,所有图片的存储结构如图所示。这么做可以直接使用pytorch的数据加载模块读取图片和类别。自己拿到一些数据集之后可以按照自己已经有的数据加载习惯来做整理。

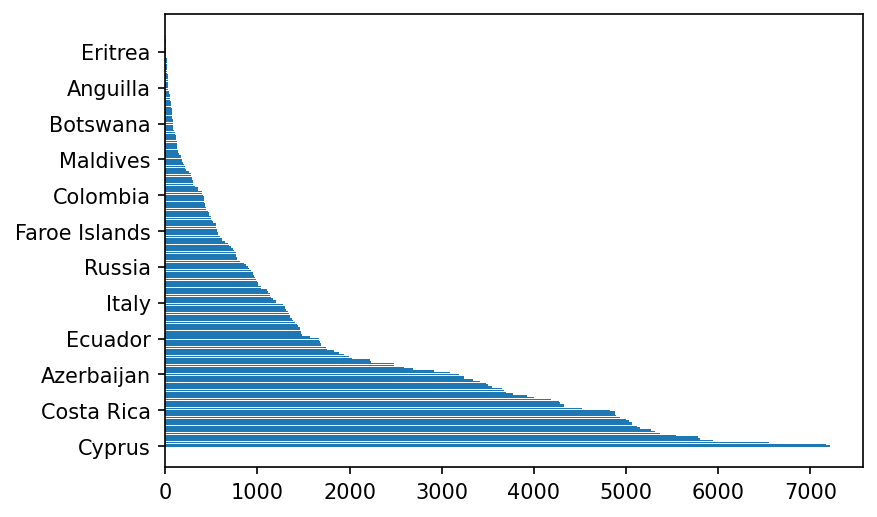
可以看一下数据各类别的分布情况。这里可以看出来自某些国家的明信片很多,而某些非常少。
show_dataset.py
import os
import matplotlib.pyplot as plt
dataset_path = './img'
name_dict = {}
for maindir, subdir, filename in os.walk(dataset_path):
if len(filename) != 0:
name_dict[os.path.basename(maindir)] = len(filename)
name_list = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
x = []
y = []
for i in name_list:
x.append(i[0])
y.append(i[1])
plt.barh(x, y)
plt.yticks(x[0:-1:20])
plt.savefig('./dataset.png', dpi=150, bbox_inches='tight')
数据清洗
数据都拿到以后,首先做一下去重和去错。防止有无法读取的图片影响训练进程,同时根据初步观察,某些国家的明信片样子有限,有很多重复的图片(但是这个去重只限于去除一图多传的情况,比如某个人用一个相同的明信片寄给了很多人,他就用同一张照片做了多个记录。但是这个方法并不能对不同发件人不同角度不同光照的同一个明信片进行很好的检测)
操作方法之前写过,参见【5分钟实例】去除大量图片中重复的图片
思路相同,只是读取的时候把路径再做一层嵌套即可。例如
if __name__ == '__main__':
dataset_path = './img'
for maindir, subdir, filename in os.walk(dataset_path):
if maindir != dataset_path:
path = maindir
# 接下来的就和之前做过的一模一样
pass
这步其实可以优化,可以通过并行的方法,同时对多个类别进行操作。因为每个类别的检测是独立的过程。
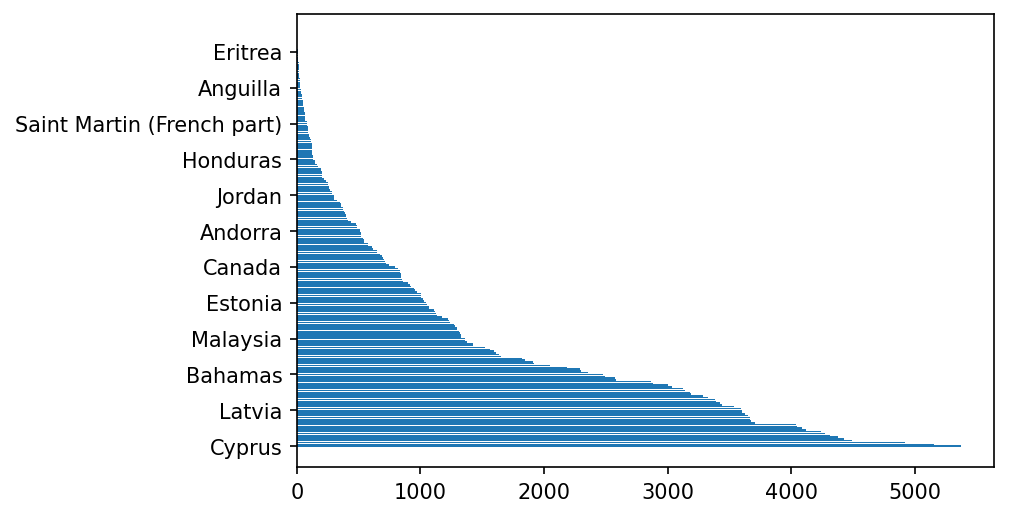
再看一下清洗之后的数据分布情况。实际的数量比例不会改变太多。
数据划分
划分至新的路径下
这样获取的数据并没有划分训练集验证集测试集,这里需要自己给他划分一下。对于每个类别下的图片文件,首先把文件顺序打乱一下,之后将文件按照23:1:1的比例划分成三个部分(即“训练集:验证集:测试集”),利用列表的长度和给定的比例计算新的训练集:验证集:测试集列表,然后根据列表里的文件名和相应的路径分别拷贝出来。【词典:train-训练,validate-验证,test-测试】(2021-01-07:修改三个集合的比例,图片总数有25万左右,验证和测试留1万个样本足矣,多留点给训练集用)
这里主要涉及的都是零碎的小操作,没什么难点,直接看代码即可:
split_train_val_test.py
import os
import random
from shutil import copyfile
dataset_path = './img'
split_folder = ['train', 'val', 'test']
split_num = [23, 1, 1]
total = sum(split_num)
for maindir, subdir, filename in os.walk(dataset_path):
if maindir != dataset_path:
random.shuffle(filename)
size = len(filename)
train_filename = filename[0 : size*split_num[0]//total]
val_filename = filename[size*split_num[0]//total : size*(split_num[0]+split_num[1])//total]
test_filename = filename[size*(split_num[0]+split_num[1])//total : ]
file_list = [train_filename, val_filename, test_filename]
for idx in range(0, 3):
os.makedirs(os.path.join(split_folder[idx], os.path.basename(maindir)))
for i in file_list[idx]:
src = os.path.join(maindir, i)
dst = os.path.join(split_folder[idx], os.path.basename(maindir), i)
copyfile(src, dst)
print(dst)
划分好的数据将分别存储在三个文件夹内。每个文件夹内也都和原本的分组文件夹格式一样
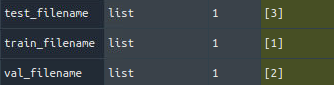
这里有一个细节的地方需要注意:如果某个类别下的图片数量太少了,怎么办?有可能没法分成三个集合。例如,如果filename这个列表太短,只有2个元素。会被划分成什么样子呢?可以通过试验观察一下
filename = [1,2,3]
split_num = [6, 2, 2]
size = len(filename)
train_filename = filename[0 : size*split_num[0]//10]
val_filename = filename[size*split_num[0]//10 : size*(split_num[0]+split_num[1])//10]
test_filename = filename[size*(split_num[0]+split_num[1])//10 : ]
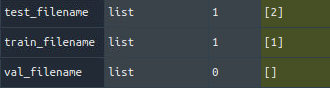
如果filename只有两个元素,会是什么样子
之所以提到这个,是因为有一些类里面样本数确实不够,但是空的文件夹并不会影响数据读取的过程,使用ImageFolder的方法,能够自动略过空的文件夹,并且不改变最终的类别数。
划分为csv格式数据
另外一种办法是,不额外将图片拷贝到分立的trian, val, test,而是使用csv列表来存储不同集合的图片路径。具体而言,和上面分文件夹存储的操作很像,只是把copy操作换成加入存储列表的操作。
使用这种方法的优点在于,可以把按照不同存储方式的多种数据集的读取工作统一起来,如果需要定制dataset的话可以省去很多麻烦。在后面将示范使用csv读取数据的优势。
img_path = ([], [], [])
img_label = ([], [], [])
for maindir, subdir, filename in os.walk(dataset_path):
......
for idx in range(0, 3):
for i in file_list[idx]:
img_path[idx].append(os.path.join('dataset', 'img', os.path.basename(maindir), i))
img_label[idx].append(os.path.basename(maindir))
经过这些操作以后,img_path和img_label里面各自存好了train, val, test对应的图片路径以及类名字了。可以用下面这个给他存成csv文件:
for idx in range(0, 3):
df = pd.DataFrame({'path':img_path[idx], 'label':img_label[idx]})
df.to_csv('./{}.csv'.format(split_folder[idx]), index=None)
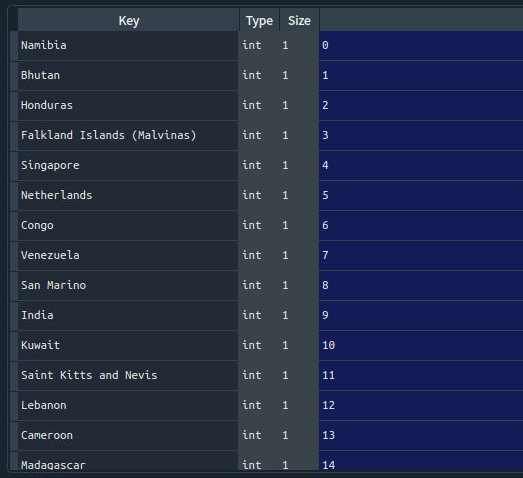
当然,实际上label都是用数字记录的,这里我们最好存的时候就把类名转化成数字。这里我们需要一个所有类名字的表,并且给他们记录好哪个类是几号。首先利用前面画数据集分布时候的一个部分,构造一个dict,只是这个dict对应的不是每个类下的样本数,而是一个编号。
name_dict = {}
flag = 0
for maindir, subdir, filename in os.walk(dataset_path):
if len(filename) != 0:
name_dict[os.path.basename(maindir)] = flag
flag += 1
由于Linux下的神奇原理,这个顺序一般不是字母表顺序。所以这个编号从0到最后就是一个看起来随机的顺序,这个倒是无所谓,反正类名和编号一一对应上了就行。
之后在img_label里就需要处理一下,将对应dict里面的类名字换成对应的编号。
img_label[idx].append(name_dict[os.path.basename(maindir)])
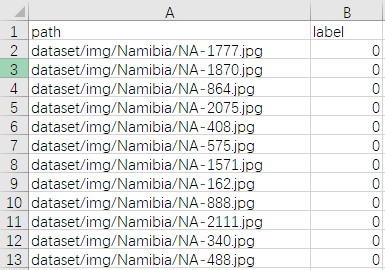
这里我们看一眼生成的csv里面是什么样子的。可以看到这个列表就是数据的“路径-对应类别”的一个个对照。(注:csv格式可以通过excel打开)
为了方便起见,可以将“名字-数字”对应表也存一下,很简单
df = pd.DataFrame.from_dict(name_dict, orient='index', columns=['label'])
df = df.reset_index().rename(columns = {'index':'country_name'})
df.to_csv('./label.csv', index=None)
还有一点,为了可能的后期操作(你也可以理解为后期又发现了这个需求,需要添加到这里),最好把每个集合下每类的数量也存下来。可以结合上面的类名与标签,顺便把各个集合下的类别数量也加在后面。这样的话,
- 原本字典赋值就需要赋一个列表,
- 后面将每个集合里面的元素数量append到字典值上,
- 最后字典列名对应也改一改。
这便是下面三处代码的变动细节:(2021-01-05 debugging:看到倒数第二行那个代码最后的[0]了吗?如果不加的话,最后会导致输出的train,val,test的标签csv的label列是一个列表,加上这个索引代表我们要img_label是数列第0个元素,即类别号。而后面的其他三个元素是划分的三个集的数量值)
......
name_dict[os.path.basename(maindir)] = [flag]
......
for idx in range(0, 3):
name_dict[os.path.basename(maindir)].append(len(file_list[idx]))
......
img_label[idx].append(name_dict[os.path.basename(maindir)][0])
df = pd.DataFrame.from_dict(name_dict, orient='index', columns=['label', 'train_cls', 'val_cls', 'test_cls'])
这便是生成的dataframe,包含了类别名,类别编号,train,val,test下的样本数量。

csv_train_val_test.py
import os
import random
import pandas as pd
dataset_path = './img'
split_folder = ['train', 'val', 'test']
split_num = [23, 1, 1]
total = sum(split_num)
img_path = ([], [], [])
img_label = ([], [], [])
cls_num = ([], [], [])
name_dict = {}
flag = 0
for maindir, subdir, filename in os.walk(dataset_path):
if len(filename) != 0:
name_dict[os.path.basename(maindir)] = [flag]
flag += 1
if maindir != dataset_path:
random.shuffle(filename)
size = len(filename)
train_filename = filename[0 : size*split_num[0]//total]
val_filename = filename[size*split_num[0]//total : size*(split_num[0]+split_num[1])//total]
test_filename = filename[size*(split_num[0]+split_num[1])//total : ]
file_list = [train_filename, val_filename, test_filename]
for idx in range(0, 3):
name_dict[os.path.basename(maindir)].append(len(file_list[idx]))
for i in file_list[idx]:
img_path[idx].append(os.path.join('dataset', 'img', os.path.basename(maindir), i))
img_label[idx].append(name_dict[os.path.basename(maindir)][0])
for idx in range(0, 3):
df = pd.DataFrame({'path':img_path[idx], 'label':img_label[idx]})
df.to_csv('./{}.csv'.format(split_folder[idx]), index=None)
df = pd.DataFrame.from_dict(name_dict, orient='index', columns=['label', 'train_cls', 'val_cls', 'test_cls'])
df = df.reset_index().rename(columns = {'index':'country_name'})
df.to_csv('./label.csv', index=None)
为了对比确认一下是不是对的,可以通过上一节用文件夹划分的结果来对比看看。经过检查是对的。其实获取各类数量的方法,也可以利用显示数据集各类分布的那步的方法来。但是前提是需要构建好三个集合的文件夹。如果直接构建csv路径列表,就只能用本节的这个方法了。既然提到这了,不如把三个集合里面的各类别数量也显示一下看看?
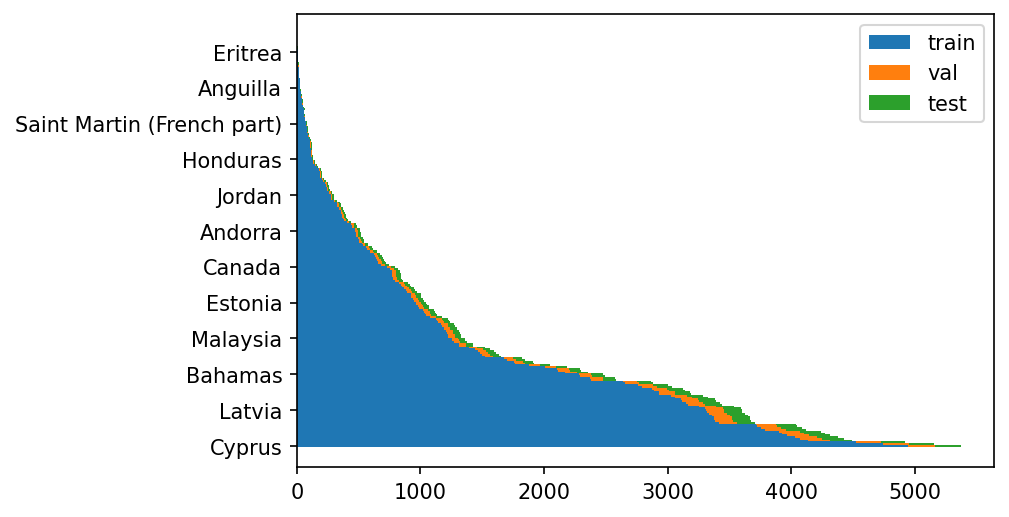
值得注意的是,第一,画叠加柱状图的时候,需要将数据转成numpy格式。第二,柱状图的条纹宽度可以改,对于横向的图,需要改的参数便为height。第三,数据排序的时候,应该以某一个为基准(例如以train样本的数量从大到小排序,然后将对应的val和test也按照这个顺序来,如若三个集合各排各的,有可能错位)
show_dataset.py
train_path = './train'
train_dict = {}
for maindir, subdir, filename in os.walk(train_path):
if len(filename) != 0:
train_dict[os.path.basename(maindir)] = len(filename)
val_path = './val'
val_dict = {}
for maindir, subdir, filename in os.walk(val_path):
if len(filename) != 0:
val_dict[os.path.basename(maindir)] = len(filename)
test_path = './test'
test_dict = {}
for maindir, subdir, filename in os.walk(test_path):
if len(filename) != 0:
test_dict[os.path.basename(maindir)] = len(filename)
train_list = sorted(train_dict.items(), key=lambda item:item[1], reverse=True)
x = []
y_train = []
y_val = []
y_test = []
for i in train_list:
x.append(i[0])
y_train.append(i[1])
y_val.append(val_dict[i[0]])
y_test.append(test_dict[i[0]])
y_train = np.array(y_train)
y_val = np.array(y_val)
y_test = np.array(y_test)
plt.barh(x, y_train, height=1, label='train')
plt.barh(x, y_val, left=y_train, height=1, label='val')
plt.barh(x, y_test, left=y_train+y_val, height=1, label='test')
plt.yticks(x[0:-1:20])
plt.legend()
plt.savefig('./split_dataset.png', dpi=150, bbox_inches='tight')
至此,前期准备工作已经完毕。
数据读取
数据准备好之后,下一步问题就是将他们读取到程序里面,如何读取?需要怎样处理?读进程序之后数据变成什么样?本章将会解答上面这些问题。
首先写一条重要的内容,关于dataloader里面的num_worker,在Linux系统和Win系统上会有一些不同的反应,Linux系统可以随意弄,但是Win系统上,要么设置为0,要么将整个内容包在main函数里(if __name__ == '__main__':)
https://blog.csdn.net/qq_38662733/article/details/108549461
程序在运行时启用了多线程,而多线程的使用用到了freeze_support()函数。
freeze_support()函数在linux和类unix系统上可直接运行,在windows系统中需要跟在main后边。
从分好类别的文件夹中读取
首先我们写以下内容
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import ImageFolder
transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomAffine(10, shear=0.1, fillcolor=(255, 255, 255)),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
transforms.RandomCrop(224, fill=(255, 255, 255)),
transforms.ToTensor()
])
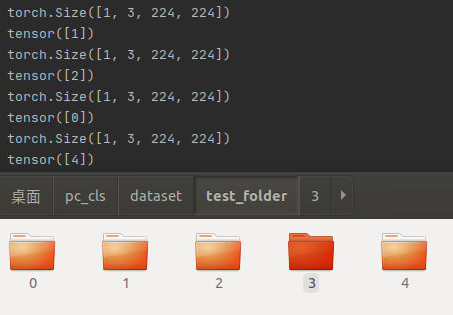
train_dataset = ImageFolder('./dataset/test_folder', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=True, num_workers=2)
transform那一堆东西后面再解释,先说train_dataset,通过ImageFolder里面写入包含一堆类别的文件夹路径,会自动将每个路径下的图片读取为Image格式的图片变量,这里注意,在用pytorch处理前需要将数据都转换为tensor格式,所以后面还写了transform用来转换数据格式,以及一些其他操作。
train_loader则是将读取来的图片数据打包成一些高维的数组,所谓高维数组,其实就是一批数据,或者说batch,而平时总听说的batch_size就是这一批数据的数据数量。举例来说,我在train_loader这里设置了batch_size是1,那这一堆数据的尺寸就是[1, 3, 224, 224],即[batch_size, RGB通道数,图片高,图片宽],shuffle是指在这一批数据里面,数据的前后顺序是否打乱,训练时一定要设置为true,否则模型可能会受到数据之间顺序的干扰(不打乱,模型就可能会记住一个batch里面类别都是连续出现,而我们希望模型更关注一批数据里面单个数据自己的情况)
利用自定义的dataset方法读取
之前我们做了csv表格,如果我们统一处理csv数据都为path-label(数据路径-数据的标签)这样的,那我们可以通过自定义的dataset方法,读取数据而无所谓数据是按什么归档方式存放的。
首先我们要有一个指导思想:自己写dataset的时候,我们需要传进所有待使用的数据的path和label的列表,之后dataset会获取这个列表的长度,作为数据总量,并且dataset会自动生成随机或者顺序的索引,迭代地从这一堆数据里获取一个个数据。
这个指导思想就对应了我们需要在dataset里面写的三个大步骤。
第一步,继承pytorch的Dataset类,定义构造函数,这里的image_path_list和label_list是两个列表,分别存储了所有待使用的数据的路径和标签。transform是对数据进行的变换。
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, image_path_list, label_list, transform=None):
self.image_path_list = image_path_list
self.label_list = label_list
self.transform = transform
第二步,获取数据数量,很简单了,列表长度就是数据数量,path列表的长度或者label列表的长度都可以,一样的。(这步必写,否则dataset不能正确的把所有数据都读取完)
def __len__(self):
return len(self.label_list)
第三步,迭代地读取每个数据。这里是一个很简单的例子,首先,这个__getitem__带有一个idx参数(你写成index,id,什么都无所谓,但是一定要有一个参数)这个参数在每次调用到这个方法的时候都会传进来(这个数的范围就是0到__len__,所以在__len__必须要有正确的长度返回),在主程序中使用dataloader去接dataset返回的数据并打包时,这个idx会自动传进来。所以这里我们将这个idx看作是一个数组的索引值即可。
def __getitem__(self, idx):
image_path = self.image_path_list[idx]
label = self.label_list[idx]
image = Image.open(image_path)
if self.transform:
image = self.transform(image)
return image, label
那么image_path就是获得到了某一个path的值,label也是同理。拿到了path,就需要将对应这个路径的图片打开,那就使用PIL下的Image.open来做,如果需要做变换就把transform塞在这里。如果需要做更多你自己对数据的魔幻操作,也在这里操作。最后的最后,需要返回一个张量image,以及一个标签label。
这里的dataset都是针对单个读进来的数据来做的。对于dataloader而言,一个batch里面的多个数据是调用了多次这个dataset的__getitem__获得的。强调这个的原因在于transform这东西,因为涉及到随机操作的transform(随机明暗,随机裁剪等)会在每次调用时初始化不同的随机数,如果想要对一个batch里的多个图片做相同的变换,那可能就要对dataset做更复杂的操作了(可能的场景:图像分割的原图和mask蒙版、视频处理时的系列帧)。这里展开说就跑题太多了,这是某一次我自己对视频序列操作的记录,仅供参考:
对于序列图片,如果涉及到这种增广操作,我只能想到一种办法,即重写所用的transforms操作,每次调用的时候传进整个图片序列,这样就只调用了一次,也就只初始化了一个随机数,这样再去做
ColorJitter()或者RandomHorizontalFlip()等随机操作里面对张量切片,对每个切片做变换,这样一系列图片可以有相同随机数下的变换操作。如果只是要做Resize()或者ToTensor()之类的那就无所谓了,调用多少次都是一样的结果。
在做好了dataset之后,去主程序里,首先导入这个模块,并且将数据的path和label列表备好,传给他即可使用,dataloader仍然是一样的:
import pandas as pd
df = pd.read_csv('./dataset/train.csv')
image_path_list = df['path'].values
label_list = df['label'].values
train_dataset = MyDataset(image_path_list, label_list, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=2)
虽然看上去这样做比直接读文件夹麻烦了很多,但是这个做法的最大优点在于,读取图片时你可能想加入一些自己的处理方法或流程,你可以直接塞进__getitem__方法里面。而且你面对的任务,不一定每次都是图片输入,如果是其他格式的数据(视频,奇怪表格,音频),照样可以利用这一套流程来处理。
再举一个小例子,pytorch的transform没有加高斯噪声的功能,假如我想给数据主动加一些噪声,该怎么操作呢?很简单,在__getitem__里面加入即可。如下。
from skimage.util import random_noise
def __getitem__(self, idx):
image_path = self.image_path_list[idx]
label = self.label_list[idx]
image = Image.open(image_path)
if self.train:
image = np.array(image)
image = random_noise(image, mode='gaussian', var=0.005)
image = (image * 255).astype(np.uint8)
if self.transform:
image = self.transform(image)
return image, label
首先将Image图像转为numpy数组,然后使用skimage加入噪声,之后再转回整型数组。注意这里有一个判断是否为训练集的操作,我只想在训练的时候做加噪,验证或者测试就用原始数据。这样,构造函数也需要加一个参数:
def __init__(self, image_path_list, label_list, train=False, transform=None):
self.image_path_list = image_path_list
self.label_list = label_list
self.transform = transform
self.train = train
这之后需要在transform里面也加入一个操作,将这个numpy数组转回PIL的Image格式。
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.RandomAffine(10, shear=0.1, fillcolor=(255, 255, 255)),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
transforms.RandomCrop(224, fill=(255, 255, 255)),
transforms.ToTensor()
])
train_dataset = MyDataset(image_path_list, label_list, train=True, transform=train_transform)
数据预处理
这一节实际上和上一节是重合的,但是鉴于上一节的内容安排,有一些东西没写,这里就来写一下上面没展开说的部分,刚刚在dataset一块提到了关于随机transform的注意事项,这里再简单说一说transform的使用。上面使用到的transform操作是
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.RandomAffine(10, shear=0.1, fillcolor=(255, 255, 255)),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
transforms.RandomCrop(224, fill=(255, 255, 255)),
transforms.ToTensor()
])
这里利用了Compose将很多个变换操作给打包到一起,在使用的时候,就会从前到后依次执行这里面的每个变换。具体的变换参数可以查源码或者官方文档,总体来说,一般会在这里做大小调整,统一缩放或裁剪到固定大小,以便做成batch(大小不同的数据没法放一个batch里面)中间可以自己做一些随机旋转或者颜色的变化,最后统一ToTensor变成tensor格式数据。
在RandomAffine和RandomCrop里面我写了fill的颜色是白色,为的是将因为旋转或者变形等造成的图像边缘空隙填充成白色。不保持默认的一个考虑是,一般而言的明信片都是白纸印刷的,本身就可能存在有白边,而且一部分扫描件的背景也是白色的,因为自然原因(明信片摆歪了)产生的图片边缘缝隙很少会有纯黑的情况。【另外的一个考虑是,为了增加这一篇内容的丰富程度,使读者明白还有这种选项可以操作】。
经过数据增广可以增加一些数据量,让模型能对图片本身的旋转或者明暗变化等等干扰有一定的容忍。
在得到了马上就可以进模型炼丹的数据之后,最好先输出一下看看,避免有奇怪的情况发生(有时候可能图片全是0,或者标签读的不对)。在开搞之前就把这些问题解决,避免丹炼糊了才发现问题,浪费时间与精力。
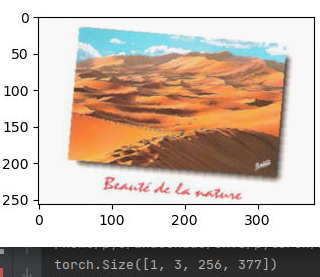
首先你可以用plt来imshow查看
for img, label in train_loader:
print(img.shape)
print(label)
plt.imshow(img[0].permute(1, 2, 0))
plt.show()
这样写,运行后你会看到这样。图片显示的是这一个batch内的第0号图片的内容。
但是这样你得关掉窗口才能看下一个图,一遍一遍点的很烦。这里用一个小工具,后面也会用到:tensorboard,这是一个可视化的工具,而且可以搭配服务器等使用,尤其在画loss或acc曲线的时候非常方便。还能记录每个记录点的时间情况,帮助我们预估程序运行时间。关于远程服务器配置的方法请见“使用xshell连接远程服务器的tensorboard”。
在pytorch中连接tensorboard非常简单,首先使用以下固定套路的代码:
import os
import time
from torch.utils.tensorboard import SummaryWriter
from tensorboard import notebook
log_dir = './log'
timestamp = time.strftime('%Y-%m-%d-%H_%M_%S', time.localtime(time.time()))
notebook.start("--logdir {}".format(log_dir))
writer = SummaryWriter(os.path.join(log_dir, timestamp))
这个写法就会在目录下面的log文件夹里,存放tensorboard生成的日志文件,按照时间戳存放。并且会自动打开一个localhost端口6006(或者其他端口)来让你访问tensorboard界面。点这个链接就行。
然后在刚刚plt.imshow的地方,替换成下面的代码
for step, (img, label) in enumerate(train_loader):
print(img.shape)
print(label)
if step % 10 == 0:
writer.add_images('train_img', img, step)
writer.close()
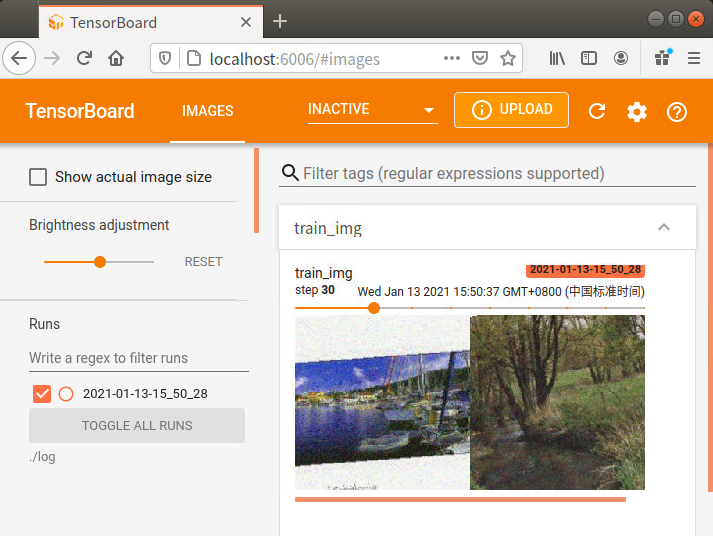
这样就会每隔10步,生成一次batch内的图片的预览样例。拖动图片上面那条进度条就可以切换查看各步的结果。
神经网络识别
一般大家都是有显卡才去炼丹的,所以首先我们先指定一下设备。这里的cuda: 0是指使用哪一个设备,对于多卡并行的设置方法,可以参考“pytorch训练加速方案整理”
import torch
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
炼丹前先测试
终于到了开火炼丹的步骤了!但是不要马上就拿着那一堆数据直接莽,首先,我们需要先试一试小批量的数据能不能完整的运行完一个流程。这样做的好处在于,你写的程序有极大的可能在训练转验证的时候出bug断掉,又或者在训练的时候用的模型输入输出总是报错。用全量数据,折腾很久才能发现这种问题,用小数据量先测试一遍,没问题的话再火力全开。
在前面的基础上,我只取前200个数据先试一试流程的完整性。
df = pd.read_csv('./dataset/train.csv')
image_path_list = df['path'].values
label_list = df['label'].values
train_size = 200
image_path_list = image_path_list[:train_size]
label_list = label_list[:train_size]
train_dataset = MyDataset(image_path_list, label_list, train=True, transform=train_transform)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=2)
验证集同理,验证集的shuffle可以关掉不要,transform保留一个Resize和ToTensor即可。
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
df = pd.read_csv('./dataset/val.csv')
image_path_list = df['path'].values
label_list = df['label'].values
val_size = 20
image_path_list = image_path_list[:val_size]
label_list = label_list[:val_size]
val_dataset = MyDataset(image_path_list, label_list, transform=val_transform)
val_loader = DataLoader(val_dataset, batch_size=10, shuffle=False, num_workers=2)
这里大家会发现,如果我想调整batch_size很麻烦,要调两个地方,而且还要来中间找代码。所以可以把它写成一个变量BATCHSIZE,放在程序最前面。
根据任务需求,设置损失函数,这里分类任务直接用交叉熵即可,网络用一个万金油网络resnet,网络可以指定最后输出的节点数量,即分类数,这个数就是你的数据的类别数量,例如这里明信片有230个国家地区,类别数就是230。测试阶段用这个最简单的模型能测通,再考虑换自己魔改的损失函数或魔幻网络,不然程序不通你都说不清是流程问题还是网络问题。优化器一般就是用Adam或者SGD,在最后试验阶段可以换着试试对比一下效果。
from torch.nn import CrossEntropyLoss
from torchvision.models import resnet50
from torch.optim import Adam
net = resnet50(num_classes=230).to(DEVICE)
loss_func = CrossEntropyLoss().to(DEVICE)
optimizer = Adam(net.parameters(), lr=0.001)
之后直接走流程,下面这个可以作为标准化模块用。这一套流程的意思是,我们执行2个轮次(epoch),每轮次我们都首先训练网络,对训练集内的数据遍历一遍,利用每次模型计算的结果与真值的误差值,反向传播优化网络的参数。所有训练数据都走了一遍以后,这一轮网络的优化就完成了。
然后进行验证,将网络的内部节点的权值都固定住,并且不求梯度,只向前计算结果。把所有验证集的数据遍历一遍,得到所有的预测结果,以及这些结果与真值的误差值。这里的误差值不再反向传播,只是算出来给我们看一眼。
for epoch in range(2):
net.train()
for step, (train_img, train_label) in enumerate(train_loader):
train_img, train_label = train_img.to(DEVICE), train_label.to(DEVICE)
predict = net(train_img)
loss = loss_func(predict, train_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
net.eval()
with torch.no_grad():
for step, (val_img, val_label) in enumerate(val_loader):
val_img, val_label = val_img.to(DEVICE), val_label.to(DEVICE)
predict = net(val_img)
loss = loss_func(predict, val_label)
同样的,如果我想增加循环轮次,很麻烦,还要来中间找到这个循环,所以我也可以把它记为EPOCH,然后放在程序最开头。
但是我们现在还没有办法看一眼中间的过程,尤其是我们最想看一看训练集的准确率变化情况,所以我们得记录一下训练时候的预测与真值对应状况。这时候就需要做一些改动,往这个标准流程里面加一些能输出显示的东西。
还记得前面的tensorboard吗?不要再用print输出一大堆数字了,结合tensorboard可以实时画出损失,准确率等的曲线。
首先一个问题是,怎样得到模型预测的准确率?模型输出的结果是一个向量,这个向量里面最大值的位置代表这个预测的最大可能类别。输出的向量转化为类别可以用predict.max(1)[1]得到,而统计预测结果正确数量以及正确率则可以用以下方法:
correct += predict.max(1)[1].eq(train_label).sum().item()
acc = correct / (BATCHSIZE * (step+1))
可以综合使用print输出结果,监视进度,以及tensorboard输出曲线,观察趋势。值得注意的是,tensorboard的writer.add的第三个参数,步数是代表了当前添加的点所处横坐标的位置。
import math
total_step = math.ceil(train_size / BATCHSIZE)
writer.add_scalar("train/loss", loss, step + 1 + epoch * total_step)
writer.add_scalar("train/acc", acc, step + 1 + epoch * total_step)
writer.add_images("train/img", train_img, step + 1 + epoch * total_step)
print('Epoch: {:d} Step: {:d} / {:d} | acc: {:.4f} | LR: {:.6f}'.format(
epoch, step + 1, total_step, acc, optimizer.param_groups[0]['lr']))
tensorboard输出如图所示。print的信息也能显示当前的epoch和剩余步数、准确率、学习率。点image进去也能看到训练和验证的图片,感觉太小的话,点一下图片就能放大。
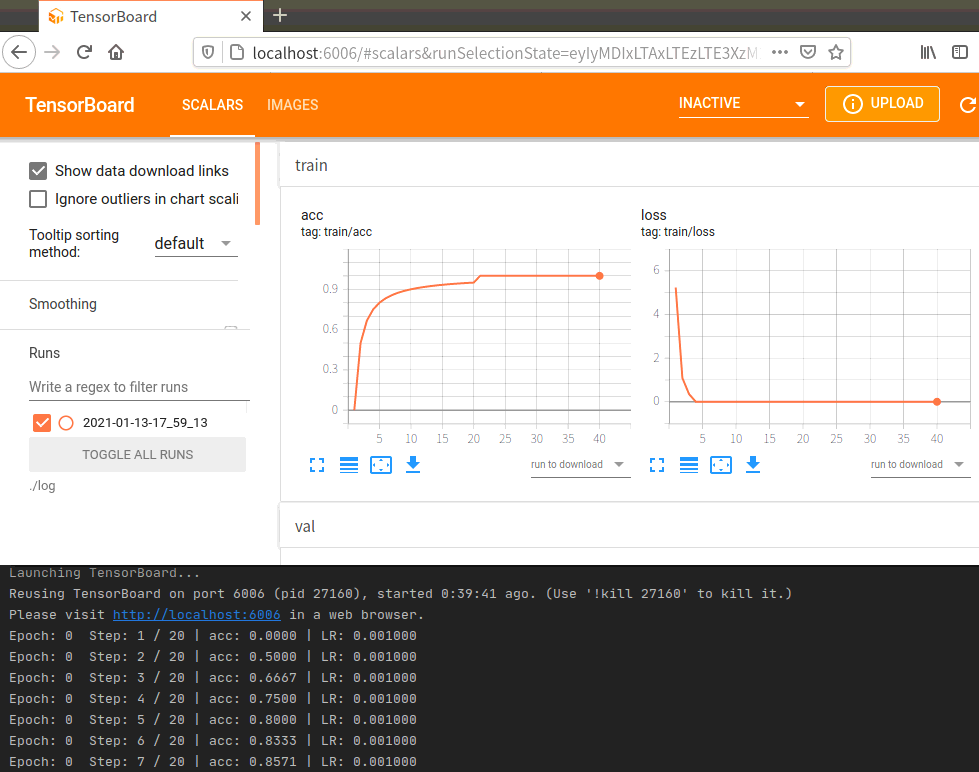

验证部分的代码如下,和训练部分的代码大同小异。
net.eval()
correct = 0
with torch.no_grad():
for step, (val_img, val_label) in enumerate(val_loader):
val_img, val_label = val_img.to(DEVICE), val_label.to(DEVICE)
predict = net(val_img)
loss = loss_func(predict, val_label)
correct += predict.max(1)[1].eq(val_label).sum().item()
acc = correct / (BATCHSIZE * (step + 1))
writer.add_scalar("val/loss", loss, step + 1 + epoch * total_val_step)
writer.add_scalar("val/acc", acc, step + 1 + epoch * total_val_step)
writer.add_images("val/img", val_img, step + 1 + epoch * total_val_step)
print('Epoch: {:d} Step: {:d} / {:d} | acc: {:.4f} | LR: {:.6f}'.format(
epoch, step + 1, total_val_step, acc, optimizer.param_groups[0]['lr']))
加载预训练权重
有时候我们想要拿已经在大数据集上训练好的模型参数来微调模型,如果使用的是pytorch自带的模型,可以直接设置pretrained=True。但是要注意一点,这样就不能直接指定num_classes的数量了,需要用以下方法来改最后一层:
net = resnet50(pretrained=True)
fc_features = net.fc.in_features
net.fc = torch.nn.Linear(fc_features, 230)
net = net.to(DEVICE)
同理这招也适合自己设计的网络训练完毕但是想要改最后一层,详见下一节。
用自己的网络
假设你现在自己写了一个网络结构。那么直接在net部分加载自己的网络模型即可。其他操作和前面的基本是一样的。加载预训练权重的话,由于是你存在本地的一个pth文件,所以在上一步的net = net.to(DEVICE)后面,通过net.load_state_dict(torch.load(pretrained_model_path))读取即可。
试一个最佳的batch_size
一般我会喜欢盯着显存大小调batch_size,当某个大小刚好不超显存的时候即为最佳。这时候GPU可以达到最佳利用率,但是CPU或者磁盘有时候会成为瓶颈。如果GPU利用率总是在100%-0%来回波动,可能是数据读取部分拖了后腿。一种方法是把数据挂载在内存里,例如ubuntu挂载硬盘(或内存盘)方法,以及增加dataloader的num_worker数量,但是也不是越多越快,需要自己试验来得到一个较好的值。
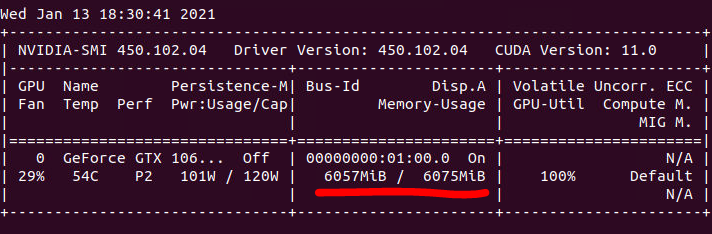
在验证最佳点保存
当验证集目前的准确率是历史最好的情况时,就把现在的模型保存。代码如下:
best_acc = 0
for epoch in range(EPOCH):
......
with torch.no_grad():
......
if acc > best_acc:
best_acc = acc
torch.save(net.state_dict(), './log/{}/{}.pth'.format(timestamp, timestamp))
print('Best acc: {:.4f}, model saved!'.format(acc))
保存模型的时候,有一个小坑:如果在使用DataParallel联动多显卡训练的时候,保存模型要用torch.save(model.module.state_dict(), model_out_path),详见多GPU并行情况下:Missing key(s) in state_dict: "conv_1.weight", "bn1.weight", "bn1.bias",
变化的学习率
通过torch.optim.lr_scheduler下面的多个学习率调整部件,可以使学习率随着训练步数的改变而变化。具体用法首先定义一个学习率调整器
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50], gamma=0.1)
具体每种调整器的参数以及情况可以查看源码内的注释,或者在训练时绘制学习率曲线直接观察。将学习率显示出来的方法是
print(optimizer.param_groups[0]['lr'])
当然你也可以结合tensorboard来显示。
定义好学习率调整器之后,需要在训练的中途给他传递信号,使他往下变化。按照以下格式做
for epoch in range(EPOCH):
net.train()
for step, (train_img, train_label) in enumerate(train_loader):
pass
scheduler.step()
net.eval()
with torch.no_grad():
for step, (val_img, val_label) in enumerate(val_loader):
pass
即训练完一次训练集之后就变化一次调整器里面的计数,根据计数情况改变学习率。
超参数管理
前面提到了对于epoch或者batchsize等参数可以单独提到程序开头来,其实还有一种方法来管理超参数,使用python自带的argparse,使用下面的代码定义需要的超参数:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--EPOCH", default=200, type=int, help="train epochs")
parser.add_argument("--BATCHSIZE", default=1024, type=int, help="batch size")
parser.add_argument("--LR", default=0.001, type=float, help="learning rate")
parser.add_argument("--LOGSTEP", default=10, type=int, help="steps between printing logs")
parser.add_argument("--NUMWORKER", default=18, type=int, help="dataloader num_worker")
parser.add_argument("--NETWORK", default='resnet', type=str, help="network structure",
choices=['resnet', 'senet', 'repvgg'])
opt = parser.parse_args()
需要调用指定的参数时,使用opt.EPOCH即可。这样做的一个优点是,可以利用批量的bash脚本或者cmd脚本来自动执行程序。例如我想执行三次这个程序,分别用三个网络结构执行完整的流程。如果自己坐在电脑前面守着程序运行完去手动点,会很烦,如果使用这种超参数指定的方法,可以在命令行内往里传递参数。
例如写以下的bash脚本:
python main.py \
--NETWORK resnet
python main.py \
--NETWORK senet
python main.py \
--NETWORK repvgg
就等同于在命令行内直接执行那三段指令。对于参数NETWORK后接的值resnet,就等于将这个值resnet作为程序里的opt.NETWORK的值进行。对于未写明值的那些参数,将按照parser里面给的默认值来执行。
想把超参数的取值记下来也可以通过以下方法直接输出
import json
parser = argparse.ArgumentParser()
parser.add_argument("--EPOCH", default=200, type=int, help="train epochs")
opt = parser.parse_args()
print(json.dumps(vars(opt)))

可视化分析
(未完待续)